我正在使用 Python Spark 将数据帧写入 blob 中的文件夹,该文件夹保存为零件文件:
df.write.format("json").save("/mnt/path/DataModel")
文件保存为:

我正在使用以下代码将其合并到一个文件中:
#Read Part files
path = glob.glob("/dbfs/mnt/path/DataModel/part-000*.json")
#Move file to FinalData folder in blbo
for file in path:
shutil.move(file,"/dbfs/mnt/path/FinalData/FinalData.json")
But FinalData.Json only have last part file data and not data of all part files.
最佳答案
我看到你只是想简单地将这些文件的内容合并到一个文件中,但是由于shutil.move函数的描述如下图所示,它的功能就像Linux mv,所以最后一个文件的内容会覆盖前面文件的内容。

而代码写入多个文件的原因是Spark工作在HDFS上,所以超过128MB(HDFS部分文件大小)的数据写入HDFS上会生成多个以part为前缀的文件,请引用What is Small file problem in HDFS ? .
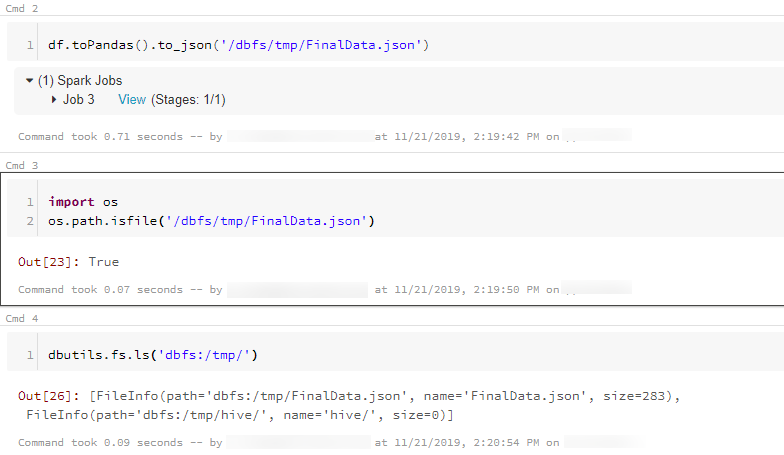
满足您需求的解决方案是将 PySpark 数据帧转换为 Pandas 数据帧,然后使用 pandas 数据帧函数 to_json 写入 json 文件。
这是我的示例代码。
df.toPandas().to_json('/dbfs/mnt/path/FinalData/FinalData.json')
然后检查文件是否存在。
import os
os.path.isfile('/dbfs/mnt/path/FinalData/FinalData.json')
或者
dbutils.fs.ls('dbfs:/mnt/path/')
作为引用,下图是我的结果。
对于您的另一个问题,使用 PySpark 读取零件文件是将通配符路径传递给函数 spark.read.json() ,如下代码所示。
spark.read.json('dbfs:/mnt/path/DataModel/part-*.json')
关于python - Azure 数据 block : How to read part files and save it as one file to blob?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/58964745/