尝试在 Synapse Studio 中运行以下简单命令时出现以下错误
df = spark.read.load('abfss://<a href="https://stackoverflow.com/cdn-cgi/l/email-protection" class="__cf_email__" data-cfemail="7e0d0a110c1f191b180d4f3e0d0a110c1f191b4f501a180d501d110c1b500917101a11090d50101b0a" rel="noreferrer noopener nofollow">[email protected]</a>/somefilepath.parquet', format='parquet')
值得一提的是:
- 我已将自己定义为存储上的存储 Blob 数据贡献者
- 我的同事负责管理 - 他运行完全相同的 Notebook,并且它对他有用。
- 我们比较了分配的角色,它们看起来很相似
- 我已将我的 PC IP 添加到“网络”页面以排除在防火墙中
- 如果我打开 Azure 存储资源管理器,我可以成功访问/编辑 Azure 存储,不会出现任何问题
An error occurred while calling o755.load. : java.nio.file.AccessDeniedException: Operation failed: "Server failed to authenticate the request. Please refer to the information in the www-authenticate header.", 401, HEAD, https://storage1.dfs.core.windows.net/storagefs1/?upn=false&action=getAccessControl&timeout=90 at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.checkException(AzureBlobFileSystem.java:1185) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.getFileStatus(AzureBlobFileSystem.java:504) at org.apache.hadoop.fs.FileSystem.isDirectory(FileSystem.java:1713) at org.apache.spark.sql.execution.streaming.FileStreamSink$.hasMetadata(FileStreamSink.scala:47) at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:377) at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:332) at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:315) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:315) at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:241) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:238) at java.lang.Thread.run(Thread.java:750) Caused by: Operation failed: "Server failed to authenticate the request. Please refer to the information in the www-authenticate header.", 401, HEAD, https://storage1.dfs.core.windows.net/storagefs1/?upn=false&action=getAccessControl&timeout=90 at org.apache.hadoop.fs.azurebfs.services.AbfsRestOperation.execute(AbfsRestOperation.java:207) at org.apache.hadoop.fs.azurebfs.services.AbfsClient.getAclStatus(AbfsClient.java:783) at org.apache.hadoop.fs.azurebfs.services.AbfsClient.getAclStatus(AbfsClient.java:765) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.getIsNamespaceEnabled(AzureBlobFileSystemStore.java:294) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.getFileStatus(AzureBlobFileSystemStore.java:785) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.getFileStatus(AzureBlobFileSystem.java:502) ... 19 more
---------- ~/cluster-env/clonedenv/lib/python3.8/site-packages/py4j/java_gateway.py in call(self, *args) 1303 answer = self.gateway_client.send_command(command) -> 1304 return_value = get_return_value( 1305 answer, self.gateway_client, self.target_id, self.name)
/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py in deco(a, *kw) 110 try: --> 111 return f(a, *kw) 112 except py4j.protocol.Py4JJavaError as e:
~/cluster-env/clonedenv/lib/python3.8/site-packages/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name) 325 if answer[1] == REFERENCE_TYPE: --> 326 raise Py4JJavaError( 327 "An error occurred while calling {0}{1}{2}.\n".
Py4JJavaError: An error occurred while calling o755.load. : java.nio.file.AccessDeniedException: Operation failed: "Server failed to authenticate the request. Please refer to the information in the www-authenticate header.", 401, HEAD, https://storage1.dfs.core.windows.net/storagefs1/?upn=false&action=getAccessControl&timeout=90 at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.checkException(AzureBlobFileSystem.java:1185) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.getFileStatus(AzureBlobFileSystem.java:504) at org.apache.hadoop.fs.FileSystem.isDirectory(FileSystem.java:1713) at org.apache.spark.sql.execution.streaming.FileStreamSink$.hasMetadata(FileStreamSink.scala:47) at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:377) at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:332) at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:315) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:315) at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:241) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:238) at java.lang.Thread.run(Thread.java:750) Caused by: Operation failed: "Server failed to authenticate the request. Please refer to the information in the www-authenticate header.", 401, HEAD, https://storage1.dfs.core.windows.net/storagefs1/?upn=false&action=getAccessControl&timeout=90 at org.apache.hadoop.fs.azurebfs.services.AbfsRestOperation.execute(AbfsRestOperation.java:207) at org.apache.hadoop.fs.azurebfs.services.AbfsClient.getAclStatus(AbfsClient.java:783) at org.apache.hadoop.fs.azurebfs.services.AbfsClient.getAclStatus(AbfsClient.java:765) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.getIsNamespaceEnabled(AzureBlobFileSystemStore.java:294) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.getFileStatus(AzureBlobFileSystemStore.java:785) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.getFileStatus(AzureBlobFileSystem.java:502) ... 19 more
问题出在哪里?
最佳答案
• 您收到此错误的原因是,您在存储帐户上没有“存储 Blob 数据贡献者”角色,也没有用于执行此命令的用户 ID未分配为 Synapse 工作区的用户或 Spark 管理员角色。
• 请在我的 Azure Synapse 工作区中找到以下命令执行的快照,并检查相同的输出:-
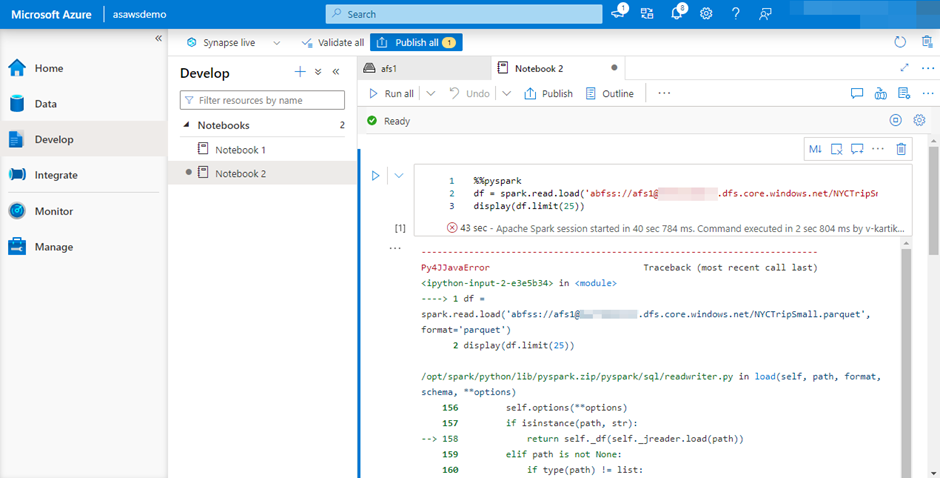
命令:- df=spark.read.load('abfss://[email protected]/somefilepath.parquet', format='parquet')
执行上述命令后出现的错误如下,这是因为我没有为我的用户 ID 分配“存储 Blob 数据贡献者”角色,因此我没有权限将角色分配给我的用户 ID,我无法分配相同的角色,因此会出现错误,否则我能够成功执行命令。
错误:- 调用 o740.load 时发生错误。 :java.nio.file.AccessDeniedException:操作失败:“此请求无权使用此权限执行此操作。”,403,HEAD
在您的场景中,无法验证对 Azure DataLake Gen 2 的访问,因为您没有在 Azure 角色分配中为您的用户 ID 分配“贡献者”角色,并且您可能也没有“贡献者”角色在 Synapse 工作区中设置管理员角色,因此您可能会遇到错误 401。
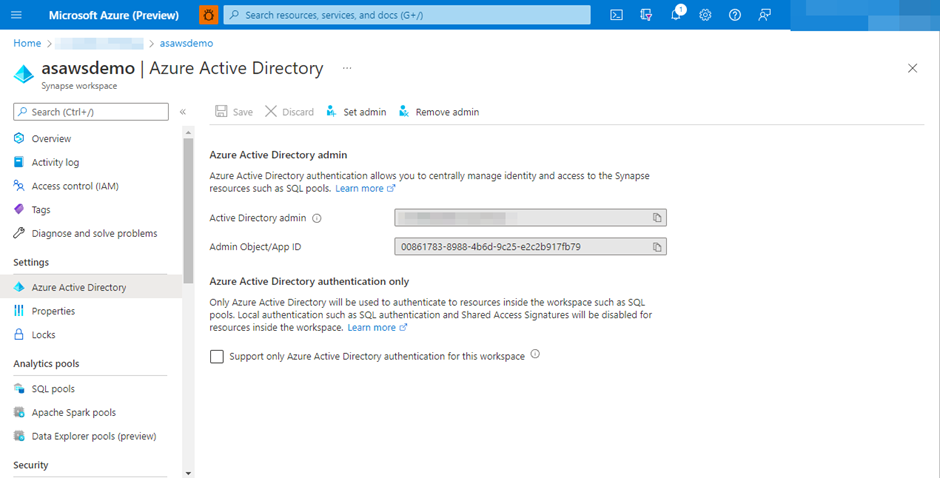
欲了解更多详细信息,请参阅以下链接:-
关于azure - 错误 401 : "Server failed to authenticate the request" while accesing data from Azure Synapse to ADLS Gens,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/73486024/