我需要 pandas groupby 方面的帮助。有没有办法对 pandas groupby 中的每个组运行 lambda(或等效函数)?请参见下面的示例。我想将上一年的百分比变化添加到此 groupby 右侧的列中。我尝试了几种方法,但它们似乎都忽略了从新的“项目”组重新开始。
import pandas as pd
x = pd.Series(['Oranges', 'Apples', 'Other Fruits', 'Oranges', 'Apples', 'Other Fruits', 'Oranges', 'Apples', 'Other Fruits'])
y = pd.Series([2016, 2016, 2016, 2017, 2017, 2017, 2018, 2018, 2018])
z = pd.Series([12, 15, 9, 14, 15, 50, 32, 15, 12])
df = pd.DataFrame({'Item': x, 'Year':y, 'Values':z})
df=df.sort_values('Values', ascending=False)
df.groupby(['Item', 'Year']).sum()
#How do I get Percent % Values for each group as a new column right of 'Values'
我期待以下内容:
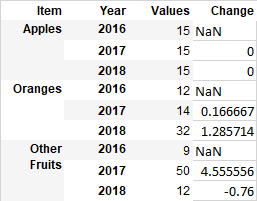
最佳答案
你正在寻找 GroupBy + apply with pct_change:
# Sort DataFrame before grouping.
df = df.sort_values(['Item', 'Year']).reset_index(drop=True)
# Group on keys and call `pct_change` inside `apply`.
df['Change'] = df.groupby('Item', sort=False)['Values'].apply(
lambda x: x.pct_change()).to_numpy()
df
Item Year Values Change
0 Apples 2016 15 NaN
1 Apples 2017 15 0.000000
2 Apples 2018 15 0.000000
3 Oranges 2016 12 NaN
4 Oranges 2017 14 0.166667
5 Oranges 2018 32 1.285714
6 Other Fruits 2016 9 NaN
7 Other Fruits 2017 50 4.555556
8 Other Fruits 2018 12 -0.760000
关于python - Groupby 对象按组的百分比变化,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/53784109/