如何访问此 API:
import requests
url = 'https://b2c-api-premiumlabel-production.azurewebsites.net/api/b2c/page/menu?id_loja=2691'
print(requests.get(url))
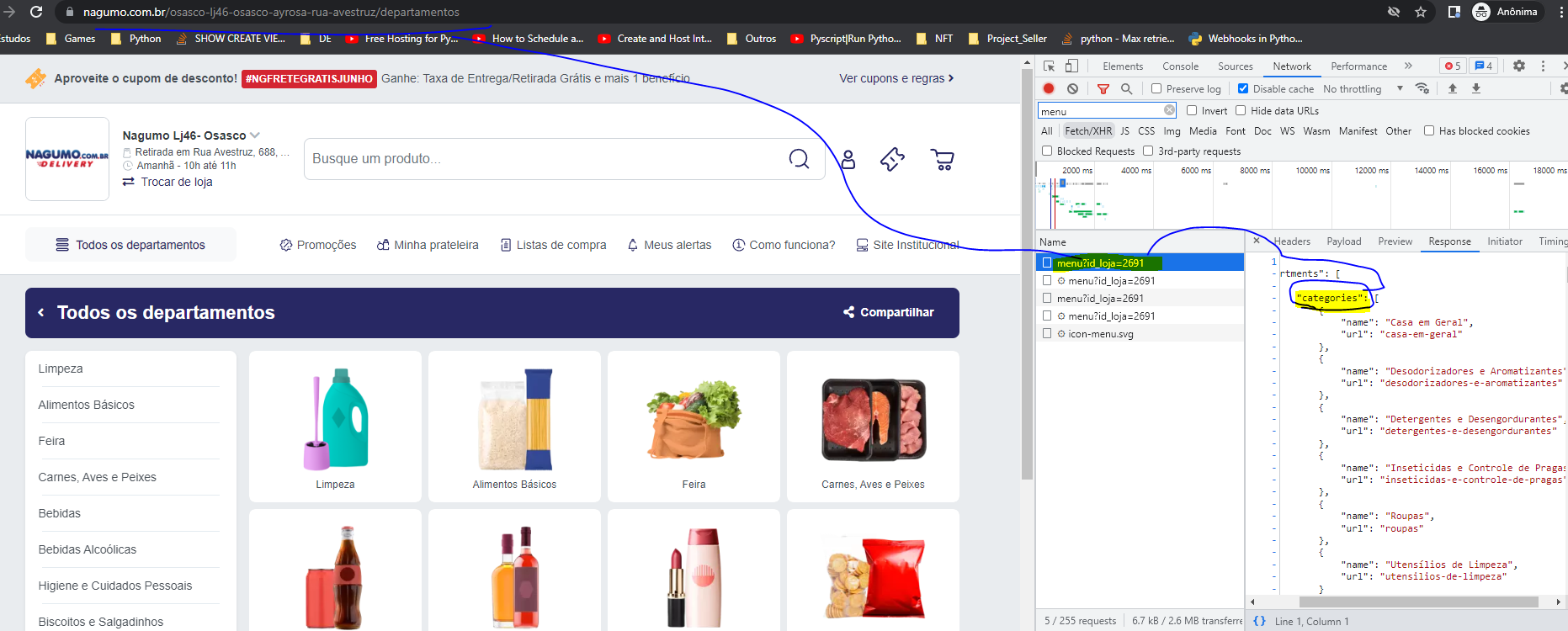
我正在尝试通过 API 从该站点检索数据,我找到了上面的 url 并且我可以看到它的数据,但是我似乎无法正确获取它,因为我遇到了代码 403。 这是网站网址: https://www.nagumo.com.br/osasco-lj46-osasco-ayrosa-rua-avestruz/departamentos
我正在尝试检索项目类别,它们对我来说是可见的,但我无法接受它们。 稍后我将使用这些类别来迭代产品 API。
{kind=link}
Obs:请保持温和,这是我在这里的第一篇文章 =]
最佳答案
要获取图像中显示的数据,需要以下 header 和端点:
import requests
headers = {
'sm-token': '{"IdLoja":2691,"IdRede":884}',
'User-Agent': 'Mozilla/5.0',
'Referer': 'https://www.nagumo.com.br/osasco-lj46-osasco-ayrosa-rua-avestruz/departamentos',
}
params = {
'id_loja': '2691',
}
r = requests.get('https://www.nagumo.com.br/api/b2c/page/menu', params=params, headers=headers)
r.json()
关于python - API - 网页抓取,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/72624886/