arr = np.arange(16).reshape((2, 2, 4))
arr.strides
(32, 16, 4)
因此,据我所知,我相信在内存中它会类似于下图。 步幅沿轴标记(在箭头上)。
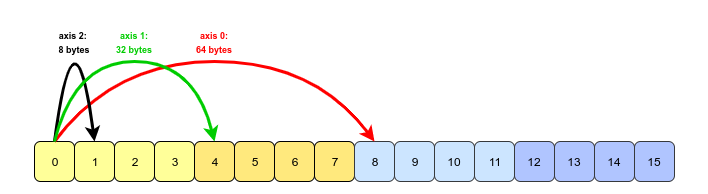
这就是我在使用命令转置其中一个轴后的想法:
arr.transpose((1, 0, 2))

我知道内存块中没有变化,但我无法理解步幅究竟如何帮助遍历内存块中的数组以生成预期的数组。 (是否将不同轴上的元素倒序遍历?)
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]]
我尝试通过 C 中的官方 numpy 代码来理解,但我无法理解。
如果有人能以更简单的方式提供解释,那就太好了。
最佳答案
除非明确要求(例如使用 axis 参数),否则 Numpy 总是从最大的轴到最小的轴迭代轴(即降序)。因此,在您的示例中,它首先读取内存中偏移量 0 处的 View 项目,然后添加轴 2 的步幅(此处为 4)并读取下一个项目,依此类推,直到到达轴的末端。然后它添加一次轴 1 的步幅并再次重复之前的循环,以此类推其他轴。
内部 Numpy C 代码的行为如下:
// Numpy array are not strongly typed internally.
// The raw memory buffer is always contiguous.
char* data = view.rawData;
const size_t iStride = view.stride[0];
const size_t jStride = view.stride[1];
const size_t kStride = view.stride[2];
for(int i=0 ; i<view.shape[0] ; ++i) {
for(int j=0 ; j<view.shape[1] ; ++j) {
for(int k=0 ; k<view.shape[2] ; ++k) {
// Compute the offset from the view strides
const size_t offset = iStride * i + jStride * j + kStride * k;
// Extract an item at the memory offset
Type item = (Type*)(data + offset);
// Do something with item here (eg. print it)
}
}
}
当您应用转置时,Numpy 会更改步幅,以便交换 iStride 和 jStride。它还会更新形状(view.shape[0] 和 view.shape[1] 也被交换)。代码将执行就像交换两个循环一样,除了内存访问效率较低,因为它们不连续。这是一个例子:
arr = np.arange(16).reshape((2, 2, 4))
arr.strides # (32, 16, 4)
view = arr.transpose((1, 0, 2))
view.strides # (16, 32, 4) <-- note that 16 and 32 have been swapped
请注意,步幅以字节为单位(而不是项目数)。
关于numpy - 步幅如何帮助遍历 numpy 中的数组?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/70366891/