具体来说,我正在尝试在 ANTLR 中实现一个 RegExp 解析器。
以下是我语法的相关部分:
grammar JavaScriptRegExp;
options {
language = 'CSharp3';
}
tokens {
/* snip */
QUESTION = '?';
STAR = '*';
PLUS = '+';
L_CURLY = '{';
R_CURLY = '}';
COMMA = ',';
}
/* snip */
quantifier returns [Quantifier value]
: q=quantifierPrefix QUESTION?
{
var quant = $q.value;
quant.Eager = $QUESTION == null;
return quant;
}
;
quantifierPrefix returns [Quantifier value]
: STAR { return new Quantifier { Min = 0 }; }
| PLUS { return new Quantifier { Min = 1 }; }
| QUESTION { return new Quantifier { Min = 0, Max = 1 }; }
| L_CURLY min=DEC_DIGITS (COMMA max=DEC_DIGITS?)? R_CURLY
{
var minValue = int.Parse($min.Text);
if ($COMMA == null)
{
return new Quantifier { Min = minValue, Max = minValue };
}
else if ($max == null)
{
return new Quantifier { Min = minValue, Max = null };
}
else
{
var maxValue = int.Parse($max.Text);
return new Quantifier { Min = minValue, Max = maxValue };
}
}
;
DEC_DIGITS
: ('0'..'9')+
;
/* snip */
CHAR
: ~('^' | '$' | '\\' | '.' | '*' | '+' | '?' | '(' | ')' | '[' | ']' | '{' | '}' | '|')
;
现在,在花括号内部,我想将“,”标记为逗号,但在大括号外部,我想将其标记为 CHAR。
这可能吗?
这不是唯一发生这种情况的案例。我将有许多其他情况出现问题(十进制数字、字符类中的连字符等)
编辑:
我知道这叫做上下文相关的词法分析。这对 ANTLR 来说可能吗?
最佳答案
this is called context-sensitive lexing. Is this possible with ANTLR?
不,解析器不能“告诉”它需要处理的词法分析器,比方说,在解析期间的某个特定时间不同的数字。单独在词法分析器中可能存在一些上下文相关的词法分析,但解析器不能影响词法分析器。
然而,它可以通过一些额外的解析器规则轻松解决。例如,在匹配字符类 ([ ... ]) 时,您使用匹配字符类中任何有效内容的解析器规则:
char_class
: LBRACK char_class_char+ RBRACK
;
// ...
char_class_char
: LBRACK // the '[' is not special inside a character class!
| LBRACE // the '{' is not special inside a character class!
| RBRACE // the '}' is not special inside a character class!
| PLUS // the '+' is not special inside a character class!
| STAR // the '*' is not special inside a character class!
| QMARK // the '?' is not special inside a character class!
| COMMA
| DIGIT
| OTHER
;
一个小演示:
grammar T;
parse
: atom* EOF
;
atom
: unit quantifier?
;
unit
: char_class
| single_char
;
quantifier
: greedy (PLUS | QMARK)?
;
greedy
: PLUS
| STAR
| QMARK
| LBRACE (number (COMMA number?)?) RBRACE
;
char_class
: LBRACK char_class_char+ RBRACK
;
number
: DIGIT+
;
single_char
: DIGIT
| COMMA
| RBRACE
| RBRACK // this is only special inside a character class
| OTHER
;
char_class_char
: LBRACK
| LBRACE
| RBRACE
| PLUS
| STAR
| QMARK
| COMMA
| DIGIT
| OTHER
;
LBRACK : '[';
RBRACK : ']';
LBRACE : '{';
RBRACE : '}';
PLUS : '+';
STAR : '*';
QMARK : '?';
COMMA : ',';
DIGIT : '0'..'9';
OTHER : . ;
它将解析输入 "[+*]{5,20}?A*+" 如下:
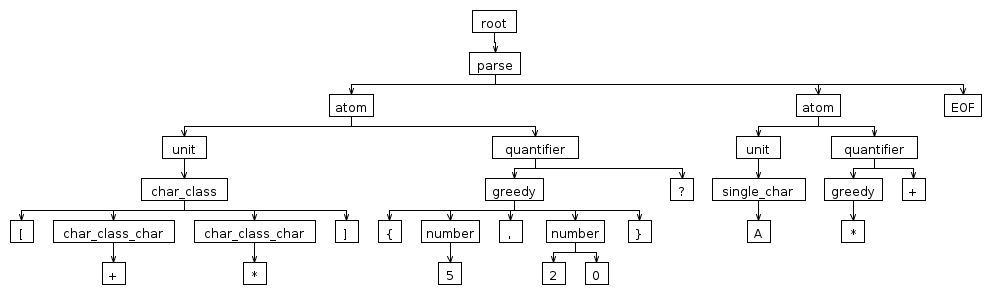
可以在这里找到更完整的 PCRE 语法:https://github.com/bkiers/PCREParser (语法可见here)
编辑
That it, I would prefer to tokenize "," as COMMA inside of the curly braces, but tokenize it as CHAR outside. I will use the workaround for now, but is that possible?
不,就像我说的:词法分析器不会受到解析器的影响。如果你想要这个,你应该去 PEG而不是 ANTLR。使用 ANTLR,词法分析和解析之间存在严格的分离:你对此无能为力。
但是,您可以只更改解析器规则中匹配的 token 类型。每个解析器规则都有一个 $start 和 $end 标记,表示它匹配的第一个和最后一个标记。由于 char_class_char(和 single_char)将始终匹配单个标记,您可以在规则的 @after block 中更改标记的类型像这样:
single_char
@after{$start.setType(CHAR);}
: DIGIT
| COMMA
| RBRACE
| RBRACK // this is only special inside a character class
| OTHER
;
char_class_char
@after{$start.setType(CHAR);}
: LBRACK
| LBRACE
| RBRACE
| PLUS
| STAR
| QMARK
| COMMA
| DIGIT
| CHAR
;
// ...
CHAR : . ;
导致您所追求的行为(我猜)。
HTH
关于c# - ANTLR:我可以让 ',' 成为一个上下文中的一个标记,而另一个在所述上下文之外吗?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/11487770/