我有一个如下所示的数据框。我想将其转换为数据透视表格式,其中每一行都有唯一 ID,每个带有类型前缀的分数都有新列。
我在实际数据框中有大约 15 种不同的类型。
df = pd.DataFrame({'ID' : [1,1,2,2,3,3,4,4],
'Type':['A','B','A','B','A','B','A','B'],
'Score':[0.3,np.nan, 0.2, 0.1, 1.1,np.nan, 2, np.nan]})
期望的输出
| 身份证 | A_Score | B_Score |
|---|---|---|
| 1 | 0.3 | |
| 2 | 0.2 | 0.1 |
| 3 | 1.1 | |
| 4 | 2 |
我在下面尝试过,它几乎可以满足我的需要,但我需要重命名列并在 pandas 数据框中需要它
df2 = df.pivot_table(index=['ID'], columns='Type')
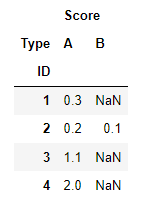
最佳答案
你可以的
out = df.pivot_table(index='ID', columns='Type',values='Score').add_prefix('Score_').reset_index()
Out[355]:
Type ID Score_A Score_B
0 1 0.3 NaN
1 2 0.2 0.1
2 3 1.1 NaN
3 4 2.0 NaN
关于python - Pandas 数据框转换为数据透视表,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/71888712/