我尝试了很多不同的方法来完成这个任务:
- 编辑
- 模糊
- Damerau Levenshtein
- 杰罗·温克勒
- Smith Waterman Gotoh
我的代码:
<?php
echo levenshtein("ЛИЧНА КАРТАlоемптY CARO Пренные ЂУРЂЕВИЋ Hercinian","Михајло Ђурђевић")."<br>";
?>
输出:
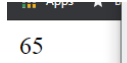
所有这些都适用于英语。然而,就我而言,我有许多不同的语言[阿拉伯语、中文、俄语...等]。这些语言中的一些字母彼此相似。
例子:
阿拉伯语中的“Ê”和“ث”
汉语"已"& "已"
俄语“ћ”和“h”
多字节语言如何处理这些字母以获得良好的准确性?
最佳答案
我只有 2 个建议。
- 使用 IntlChar::ord 将字符转换为其代码点值.
大多数时候代码点值是should also be close to the other character . (改用 Levenshtein)。
这适用于您的前 2 个示例。
- 使用 imagestring 将字符转换为图像 使用 pHash在图像上查看图像的差异。
这将适用于您的所有 3 个示例
关于php - 如何比较两个字符串 [已] , [已] 并查看彼此有多接近?使用 PHP,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/62873237/