如何使用 C# 从 PDF 或 XPS 中提取具有格式的文本?
我有一些由其他报告软件生成的 PDF/XPS 文件。该文件主要包括列出一些数据的表格。
iText 可以从 pdf 文件中提取文本,但随后丢失了一些格式,例如,对于下表,提取的文本是:
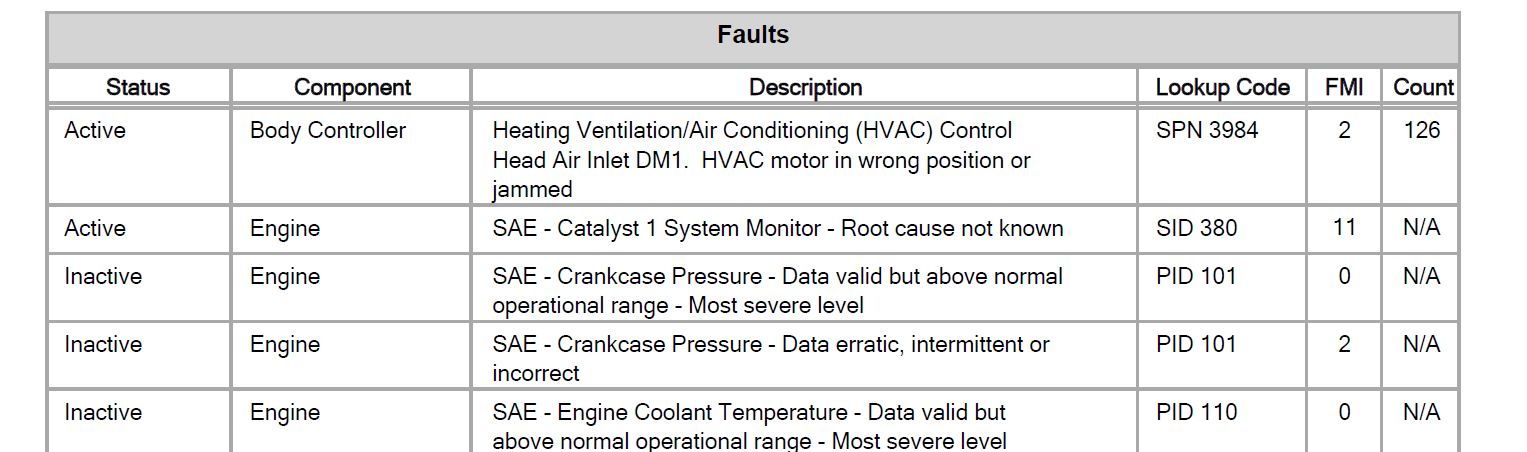
Faults
Count FMI Lookup Code Description Component Status
Active Body Controller Heating Ventilation/Air Conditioning (HVAC) Control
Head Air Inlet DM1. HVAC motor in wrong position or
jammed
SPN 3984 2 126
Active Engine SAE - Catalyst 1 System Monitor - Root cause not known SID 380 11 N/A
Inactive Engine SAE - Crankcase Pressure - Data valid but above normal
operational range - Most severe level
PID 101 0 N/A
Inactive Engine SAE - Crankcase Pressure - Data erratic, intermittent or
incorrect
PID 101 2 N/A
问题是不同列中的文本在同一行上,这使得几乎不可能确切地知道哪个文本是针对哪一列的。不幸的是,我需要将不同列中的数据保存到数据库中的不同字段。
我也试过将PDF转换成html,但后来发现html不包含实际的文本,它在html中使用了SVG。所以我无法获得实际文本。
有没有办法使用 C# 执行此操作?有什么建议么?有没有更好的免费图书馆?
谢谢
最佳答案
您可以使用 Docotic.Pdf 提取格式化文本(免责声明:我是合著者)。这是基本的示例代码:
using (var pdf = new PdfDocument("your_document.pdf"))
{
string formattedText = pdf.GetTextWithFormatting();
using (var writer = new StreamWriter("formatted.txt"))
writer.Write(formattedText);
}
示例结果:

之后,您可以通过空格检测列。例如,将 3 个以上的空格序列视为列分隔符。
您可以在 this article 中找到其他文本提取技术。 .例如,这些方法也可能有用:
- 从特定区域提取文本(如果页面包含不同的表格或常规文本与表格的混合,则很有用)
- 提取每个文本 block 的详细信息(如果您想构建自定义表格检测逻辑,这很有用)
- 使用矢量路径提取文本(如果您想在自定义表格检测算法中尊重表格边界,这很有用)
关于c# - 如何使用 C# 从 PDF 或 XPS 中提取具有格式的文本?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/62899509/