我正在寻找一种方法来获得每一行的加权平均值,其中计算出的权重根据所有先前的值减半(并且随着先前值的增加对每一行继续)。
所以像 Out[1) 这样的输出应该看起来像 Out[2]:
权重应该从 1/1 到 1/2 到 1/3 到 1/4 到 1/5...等等,这取决于之前的观察数量。
>> Out[1]:
B
0 1
1 2
2 5
3 3
Out[2]:
B
0 1
1 1.66
2 3.455
3 3.080
# Where row 1 is calculated as: (2*1/1 + 1*1/2)/(1/1 + 1/2) = 1.66,
# and row 2 as: (5*1/1 + 2*1/2 + 1*1/3)/(1/1 + 1/2 + 1/3) = 3.455,
# row 3 as: (3*1/1 + 5*1/2 + 2*1/3 + 1*1/4)/(1/1 + 1/2 + 1/3 + 1/4) = 3.080,
# ... and that way keeping forward depending on how much observations I have.
是否可以修改 pandas.ewm() 函数以获得解决方案,因为它具有类似的方法?我只是想不通如何根据之前的所有行为每一行设置权重。
也许有人能够将其转换为使用 Python 的代码?
最佳答案
您不能使用 pandas EWM 函数执行此操作。
这是因为你无法表示几何级数
S_1 = 1 + 1/2 + 1/3 + ...
在表格中
S_2 = 1 + (1 - alpha) + (1 - alpha)**2 + ...
这应该让你得到你想要的东西
import numpy as np
def rolling_mean_harmonic(x: np.ndarray) -> np.ndarray:
"""
Calculates the rolling mean using harmonic series weightings
along the first dimension of ``x``
Example:
>>> rolling_mean_harmonic(np.array([1, 2, 5, 5]))
array([1. , 1.66666667, 3.45454545, 3.08 ])
"""
out = np.empty(x.shape, dtype=np.float64)
h = (1/np.arange(1, len(x) + 1))
h_cumsum = h.cumsum()
for i in range(x.shape[0]):
out[i] = (x[:i + 1] * h[:i + 1][::-1]).sum() / h_cumsum[i]
return out
如果速度是一个问题,上面的代码可以很容易地改进并与 Numba njit + prange 并行化
编辑...
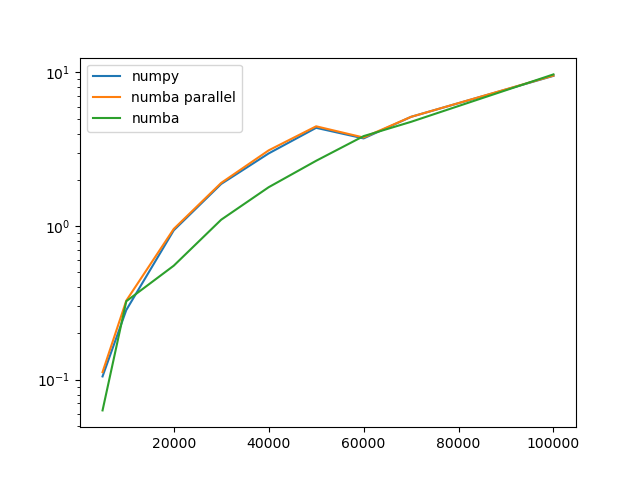
我尝试使用 numba,发现并行实际上没有加速:
import numpy as np
import numba as nb
nb.njit('float64[:](float64[:])', nogil=True, fastmath=True)
def rolling_mean_harmonic_nb_noparr(x: np.ndarray) -> np.ndarray:
"""
Calculates the rolling mean using harmonic series weightings
Example:
>>> rolling_mean_harmonic(np.array([1, 2, 5, 5], dtype=float))
array([1. , 1.66666667, 3.45454545, 3.08 ])
"""
out = np.empty_like(x)
h = (1/np.arange(1, len(x) + 1))
h_cumsum = h.cumsum()
for i in range(x.shape[0]):
out[i] = (x[:i + 1] * h[:i + 1][::-1]).sum() / h_cumsum[i]
return out
nb.njit('float64[:](float64[:])', parallel=True, nogil=True, fastmath=True)
def rolling_mean_harmonic_nb(x: np.ndarray) -> np.ndarray:
"""
Calculates the rolling mean using harmonic series weightings
Example:
>>> rolling_mean_harmonic(np.array([1, 2, 5, 5], dtype=float))
array([1. , 1.66666667, 3.45454545, 3.08 ])
"""
out = np.empty_like(x)
h = (1/np.arange(1, len(x) + 1))
h_cumsum = h.cumsum()
for i in nb.prange(x.shape[0]):
out[i] = (x[:i + 1] * h[:i + 1][::-1]).sum() / h_cumsum[i]
return out
关于python - 排名逆权重类似于 pandas.ewm(),我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/66051964/