我正在尝试查找,是否有人按照以下方式实现了二进制搜索 -
假设我们有一些元素的数组,放置在连续的内存中。
那么当你比较中间元素时,接下来的几个元素应该已经在CPU缓存中了。比较应该已经免费了吧?
但是我找不到任何人这样做。
如果没有人这样做,可能是什么原因?
最佳答案
经典的二分搜索可以认为是在元素上定义一个二叉树结构。例如,如果您的数组有 15 个元素,编号从 1 到 15,您可以从查看中间元素“8”开始,然后从那里向左或向右移动到元素“4”或“12”:

(来自 Brodal 等人,“通过小高度的二叉树缓存不经意的搜索树”,SODA'02,PDF preprint link)
您的提议实质上是在每个节点中添加更多元素,这样“8”元素也将包含一些相邻元素,例如“9”、“10”、“11”。我认为这之前没有被广泛研究过,但是已经研究了另一个非常相关的想法,即从二叉树(每个节点上有两个 child )到 B 叉树(“B 树” ,每个节点上有 B 个 child )。这是您在一个节点中有多个元素的地方,这些元素将结果数据分成许多不同的范围。
通过将搜索关键字与节点中的 B-1 个不同元素进行比较,您可以确定要递归到 B 个子节点中的哪个。
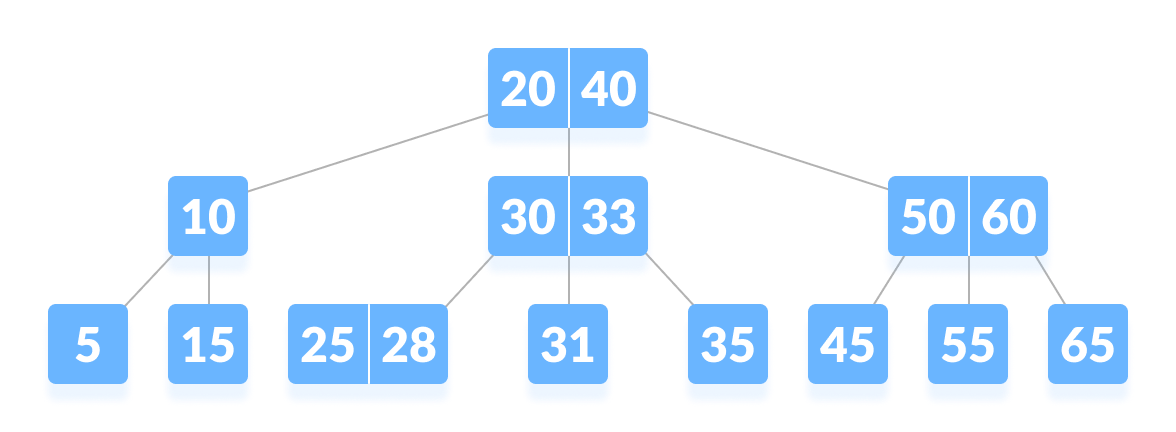
可以重新排列数组中的元素,这样就可以在不使用指针和多次内存分配的情况下实现这种搜索结构,这样它就可以像在常规排序数组中进行二分查找一样节省空间,但使用更少进行搜索时“跳跃”。在常规排序数组中,二分搜索大致执行 log_2(N) 次跳转,而 B 树中的搜索仅执行 log_2(N)/log_2(B) = log_B(N) 次跳转,这是一个因子 log_2(B) 更少!
Sergey Slotin 写了一篇博客文章,其中包含一个完整示例,说明如何实现隐式存储在数组中的静态 B 树:https://algorithmica.org/en/b-tree
关于performance - 查找附近值的二进制搜索,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/68819736/