我正在尝试查看具有以下值的变量的分布..
+-------+-------+
| Value | Count |
+-------+-------+
| 0.0 | 355 |
| 1.0 | 935 |
| 2.0 | 1 |
| 3.0 | 2 |
| 4.0 | 1 |
+-------+-------+
表格中的值最多为 1000,但非常稀疏(观测值总数 = 1622,几乎所有观测值都落在 0 或 1 内)
所以在绘图时我做了:
sns.distplot(kde=True, a = df.loc[(df.class == 1)].variable_of_interest)
产生以下红色分布

Seaborn 没有捕获值的初始集中值,但对其余值表现出更多的“敏感性”
然后我想起了 pd.DataFrame.plot.kde() ,所以我尝试了一下,它生成了这个捕获浓度的图
df.loc[(df.class== 1)].variable_of_interest.plot.kde()

重要说明:对于那些可能注意到 X 轴有所不同的人,我确实尝试了带有 xlims(-500, 1000) 的seaborn,但绘图仍然完全相同
你知道为什么它们会产生如此不同的情节吗? 这与他们处理数据的方式有关,还是我做错了什么?
提前非常感谢您!
最佳答案
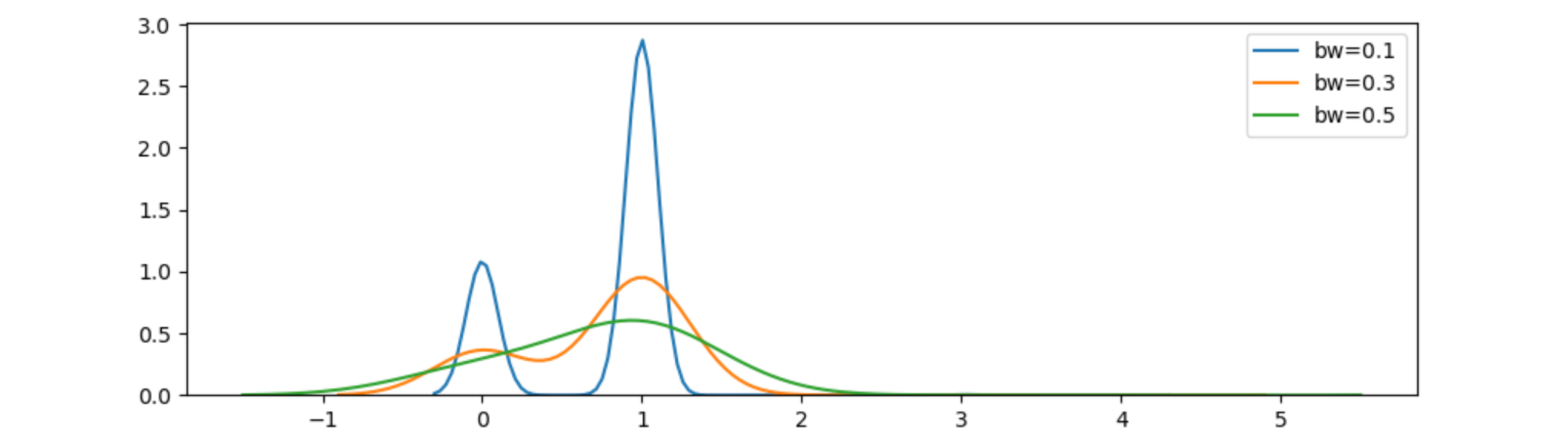
问题在于kde主要用于连续数据,而您似乎正在处理离散数据。一个重要的参数是带宽:它越小,曲线越接近数据,越宽越能表明一般形式。
看来seaborn和pandas在这里使用不同的方法来估计“良好”的带宽。与seaborn您可以设置固定带宽 sns.kdeplot(..., bw=0.5) 左右。或seaborn.distplot(..., kde=True, kde_kws={'bw': 0.5}) 。与pandas df.plot.kde(bw_method=0.5, ...)。请注意,“完美”带宽并不存在,它取决于数据、样本数量以及您对底层分布的了解。默认的seaborn和pandas选择只是一个经验法则,这可能对您的数据有用或无用。 future 的版本可能会使用不同的经验法则。
下图显示了不同带宽如何影响 kdeplot:
关于python - 为什么 Pandas 和 Seaborn 对相同的数据生成不同的 KDE 图?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/62176879/