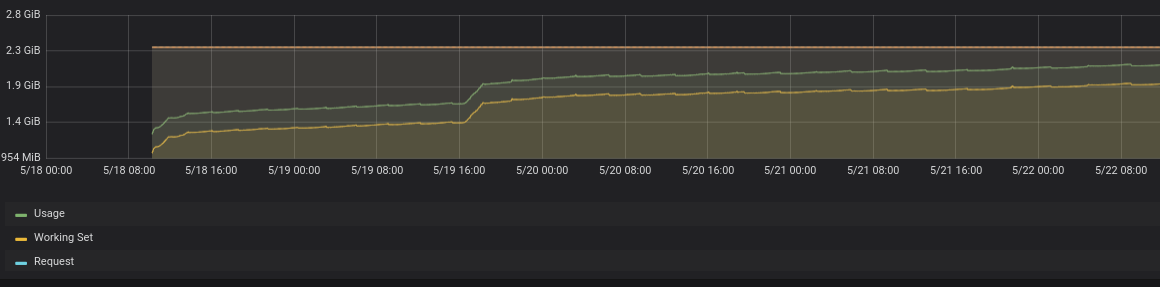
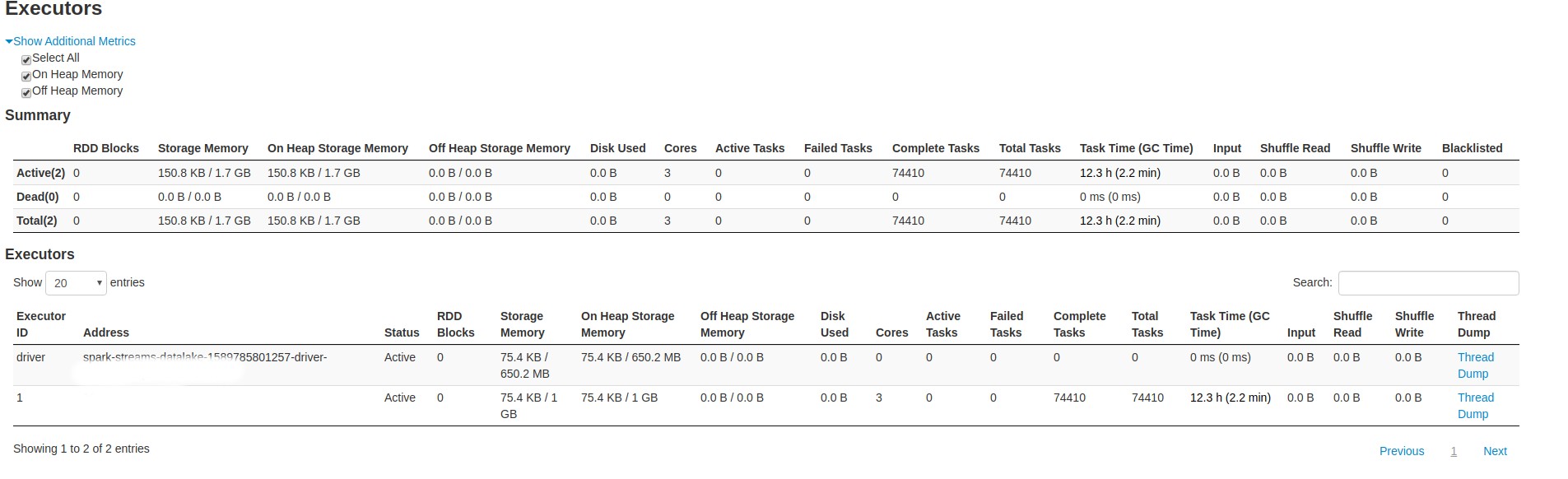
我在 k8s 运算符上部署了一个结构化流作业,它只是从 kafka 读取数据,反序列化,添加 2 列并将结果存储在数据湖中(尝试了 delta 和 parquet),几天后执行程序增加了内存,最终我得到OOM。输入记录的 kbs 真的很低。 P.s 我使用完全相同的代码,但使用 cassandra 作为接收器,现在运行了将近一个月,没有任何问题。有什么想法吗?
{kind=link}
{kind=link}
我的代码
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", MetisStreamsConfig.bootstrapServers)
.option("subscribe", MetisStreamsConfig.topics.head)
.option("startingOffsets", startingOffsets)
.option("maxOffsetsPerTrigger", MetisStreamsConfig.maxOffsetsPerTrigger)
.load()
.selectExpr("CAST(value AS STRING)")
.as[String]
.withColumn("payload", from_json($"value", schema))
// selection + filtering
.select("payload.*")
.select($"vesselQuantity.qid" as "qid", $"vesselQuantity.vesselId" as "vessel_id", explode($"measurements"))
.select($"qid", $"vessel_id", $"col.*")
.filter($"timestamp".isNotNull)
.filter($"qid".isNotNull and !($"qid"===""))
.withColumn("ingestion_time", current_timestamp())
.withColumn("mapping", MappingUDF($"qid"))
writeStream
.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
log.info(s"Storing batch with id: `$batchId`")
val calendarInstance = Calendar.getInstance()
val year = calendarInstance.get(Calendar.YEAR)
val month = calendarInstance.get(Calendar.MONTH) + 1
val day = calendarInstance.get(Calendar.DAY_OF_MONTH)
batchDF.write
.mode("append")
.parquet(streamOutputDir + s"/$year/$month/$day")
}
.option("checkpointLocation", checkpointDir)
.start()
我更改为 foreachBatch,因为将 delta 或 parquet 与 partitionBy 一起使用会导致问题更快
最佳答案
Spark 3.1.0 中解决了一个错误。
参见 https://github.com/apache/spark/pull/28904
解决问题的其他方法和调试功劳:
https://www.waitingforcode.com/apache-spark-structured-streaming/file-sink-out-of-memory-risk/read
即使您正在使用 foreachBatch,您也可能会发现这很有用......
关于apache-spark - 结构化流 OOM,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/61951953/