我正在尝试从我的数据框的一个子集中重新排序一个因子,该子集由另一个因子使用 forcats::fct_reorder() 定义。
考虑以下数据框 df:
set.seed(12)
df <- data.frame(fct1 = as.factor(rep(c("A", "B", 'C'), each = 200)),
fct2 = as.factor(rep(c("j", "k"), each = 100)),
val = c(rnorm(100, 2), # A - j
rnorm(100, 1), # A - k
rnorm(100, 1), # B - j
rnorm(100, 6), # B - k
rnorm(100, 8), # C - j
rnorm(100, 4)))# C - k
我想使用 ggridges 包绘制分面组密度。例如:
ggplot(data = df, aes(y = fct2, x = val)) +
stat_density_ridges(geom = "density_ridges_gradient",
calc_ecdf = T,
quantile_fun = median,
quantile_lines = T) +
facet_wrap(~fct1, ncol = 1)
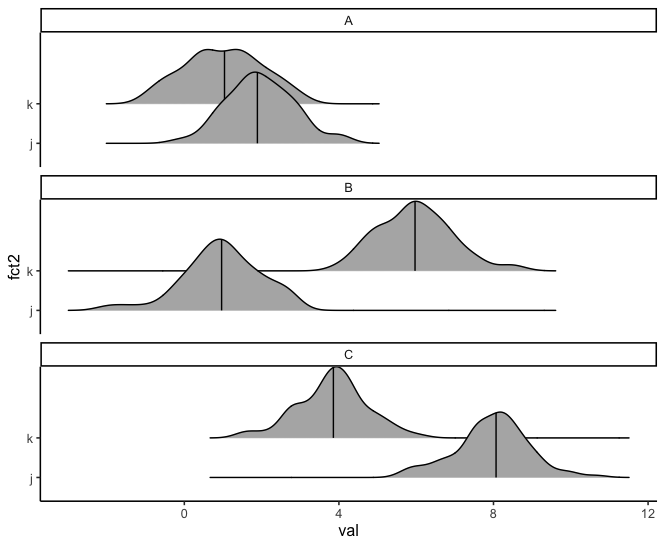
我现在想按每个面的上密度值的中位数(fct_reorder() 中的默认值)对 fct1 进行排序,即 fct2 == "k"。因此,此示例中的目标是构面按 B - C - A 的顺序出现。
这似乎与 this question here 非常相似,不同之处在于我不想先总结数据,因为我需要原始数据来绘制密度。
我已尝试在链接问题的答案中调整代码:
df <- df %>% mutate(fct1 = forcats::fct_reorder(fct1, filter(., fct2 == 'k') %>% pull(val)))
但它返回以下错误:
Error in forcats::fct_reorder(fct1, filter(., fct2 == "k") %>% pull(val)) :
length(f) == length(.x) is not TRUE
很明显它们的长度不一样,但我不太明白为什么这个错误是必要的。我的猜测是,通常不能保证 fct1 的所有级别都出现在子集中,这肯定会有问题。然而,在我的例子中情况并非如此。有没有办法解决这个错误,还是我做错了更普遍的事情?
我知道我可以通过几行额外的代码来解决这个问题,例如创建子集数据的辅助变量,对其重新排序,然后将级别顺序与原始数据集中的我的因素相匹配。我仍然想要一个更漂亮的解决方案,因为我经常面临同样的任务。
最佳答案
你可以用一个小的辅助函数来做到这一点:
f <- function(i) -median(df$val[df$fct2 == "k" & df$fct1 == df$fct1[i]])
这允许您像这样重新排序:
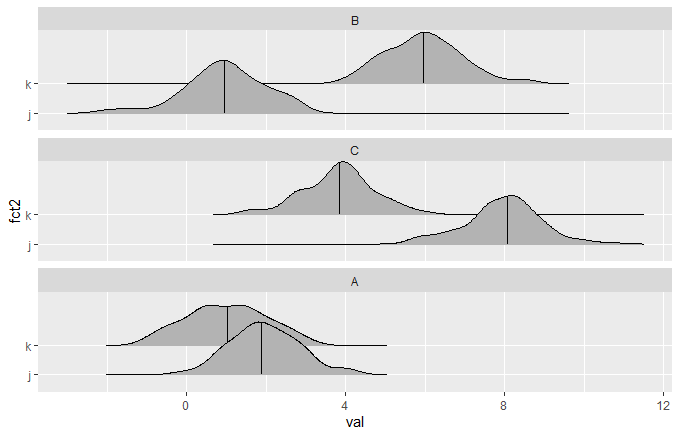
df$fct1 <- forcats::fct_reorder(df$fct1, sapply(seq(nrow(df)), f))
这给了你这个情节:
ggplot(data = df, aes(y = fct2, x = val)) +
stat_density_ridges(geom = "density_ridges_gradient",
calc_ecdf = T,
quantile_fun = median,
quantile_lines = T) +
facet_wrap(~fct1, ncol = 1)
关于根据数据子集的汇总统计对因子重新排序,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/62302753/