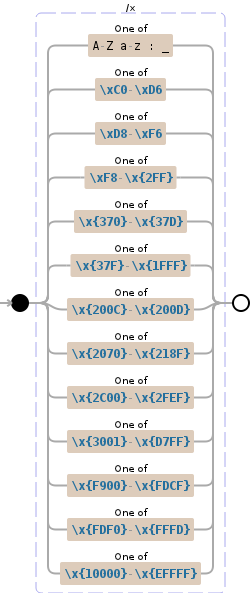
这是我的正则表达式:
(?x)(?:[A-Za-z:_] | [\\xC0-\\xD6]| [\\xD8-\\xF6] | [\\xF8-\\x{2FF}] | [\\x{370}-\\x{37D}] | [\\x{37F}-\\x{1FFF}] | [\\x{200C}-\\x{200D}] | [\\x{2070}-\\x{218F}] | [\\x{2C00}-\\x{2FEF}] | [\\x{3001}-\\x{D7FF}] | [\\x{F900}-\\x{FDCF}] | [\\x{FDF0}-\\x{FFFD}] | [\\x{10000}-\\x{EFFFF}])
Java 拒绝编译它。它引发了这个异常:
java.util.regex.PatternSyntaxException: Illegal hexadecimal escape sequence near index 68
^/((?:(?x)(?:(?x)(?:[A-Za-z:_] | [\xC0-\xD6]| [\xD8-\xF6] | [\xF8-\x{2FF}]...
^
怎么了?
Java 6
最佳答案
\x{<i>h...h</i>} java.util.regex.Pattern 中未添加带有大括号和非固定数目的十六进制数字的符号直到 Java 7:
(在页面中搜索 \x{ 。只有后一个链接有它。)
相反,您需要使用 \u<i>hhhh</i>符号:[\\xF8-\\u02FF] .
然而,\u<i>hhhh</i>表示 UTF-16 代码单元,即 Java char , 而不是完整的 Unicode 代码点,所以你的正则表达式的最后一部分 — [\\x{10000}-\\x{EFFFF}] - 翻译起来比较棘手。我认为 Java 6 正则表达式完全在代码单元上运行,因此您实际上需要将其视为两个代码单元:[\\uD800-\\uDB7F][\\uDC00-\\uDFFF] (其中 [\\uD800-\\uDB7F] 是“高”代理项的相关子范围,[\\uDC00-\\uDFFF] 是“低”代理项的整个范围;幸运的是,U+EFFFF 恰好位于具有相同高代理项的代码点范围的末尾,否则你需要做一些更复杂的事情)。 (免责声明: 未经测试。)
关于regex - 如何在没有 Java 7 的情况下匹配正则表达式字符串中大于\uFFFF 的 Unicode 代码点?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/29630195/