这是 this one 的后续问题
因此,我一直从“编程访问”的角度探索现代分析器的功能,并且遇到了一些超出我理解的事情。
这次我偶然发现了 JProfiler 中的“分配调用树”功能:
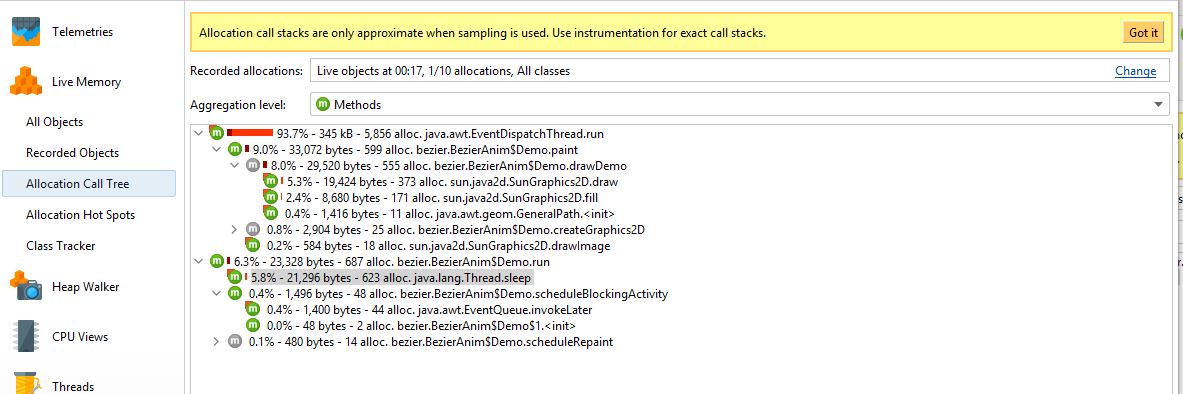
我确实看到,为了获得此类信息,我必须默认以 1/10 的比率触发抽样分配,然后指定(最好)将记录分配的分类的包。
第一步
第 2 步
但后来我真的不明白有关调用堆栈的信息如何与有关已分配对象的信息“匹配”。
当然,我的问题不是关于 JProfiler 的实现细节,我理解它是一个具有紧密代码和一切的商业工具,而是关于如何检索此类信息的一般理解。
我最初的猜测是它以某种方式“检测”已经加载的类文件以“拦截”这些对象的每一次分配(采样率不会减慢进程太多)但是然后呢?它会调用类似 Thread.currentThread().getStackTrace() 的东西并记录导致分配的实际堆栈跟踪吗?
另一方面,它在“采样模式”(与仪器相反)中激活 + 存在性能问题 - 对我来说这听起来非常昂贵(阅读,不应在生产中使用) ,但我可能是错的,所以任何建议将不胜感激。
最佳答案
My initial guess is that it somehow "instruments" the already-loaded class files to "intercept" each and every allocation for these objects
自 Java 11 交付以来 JEP 331它在 native JVMTI 中使用这些功能以对分配进行采样。在 Java 11 之前,它检测 java.lang.Object 构造函数。至于调用堆栈,则取决于是否使用检测或采样。对于检测,它使用已经由检测构建的调用堆栈。对于采样,采样构建的调用栈不够精确,所以queries the call stack through JVMTI .
Does it call something like Thread.currentThread().getStackTrace()
对于采样来说有点像那样,但是在 Java 中这样做会产生巨大的开销,因为有许多二次分配。 JVMTI 是 native 接口(interface),可以更有效地执行此操作。
关于java - JVM以编程方式获取分配调用堆栈,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/67156225/