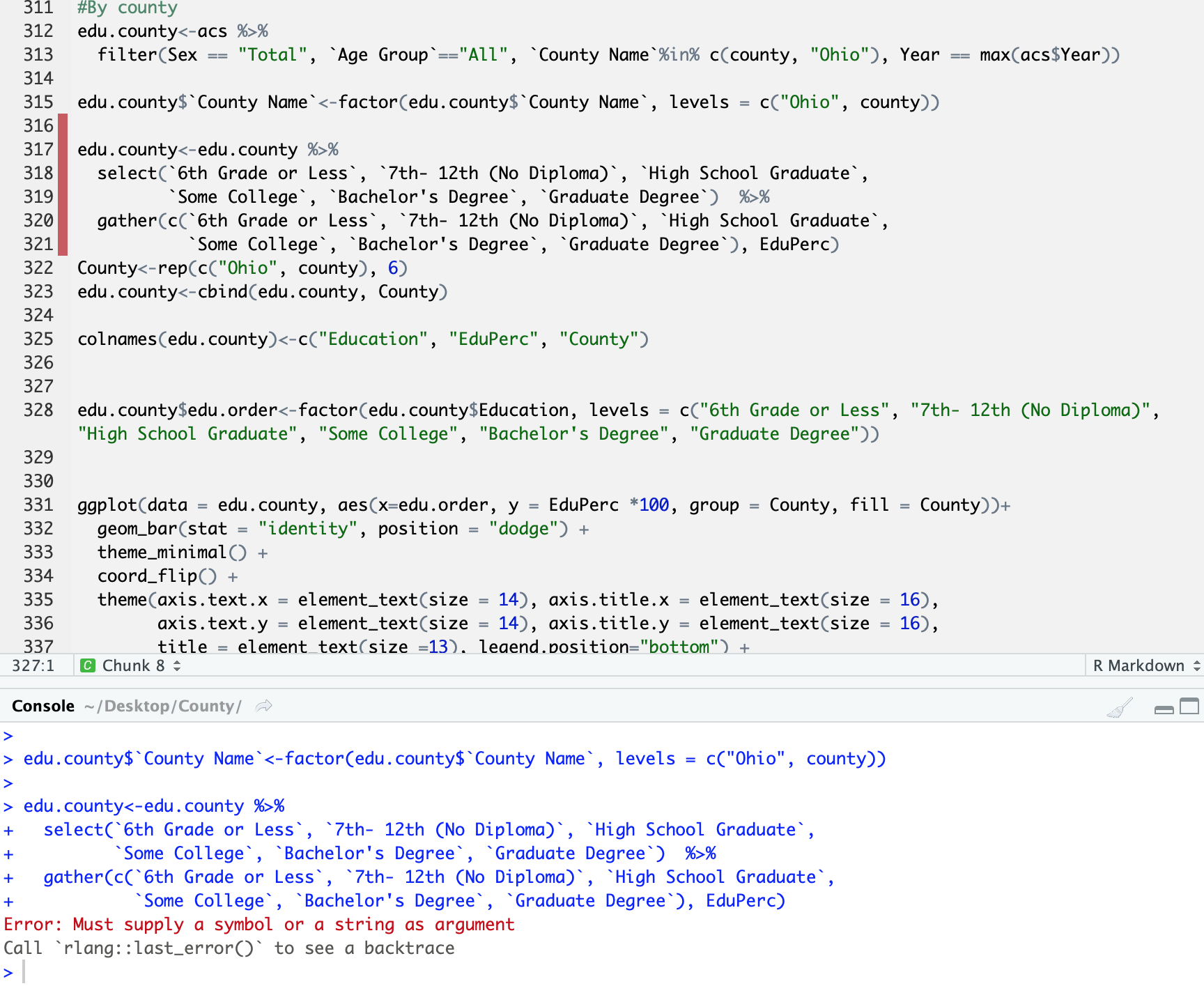
我有 R-markdown 代码,过去可以在我的笔记本电脑上正常使用。现在,当我尝试将它们编入 HTML 文件时,出现此错误:
Error: Must supply a symbol or a string as argument.
有趣的是,我的同事说这些代码在她的台式电脑上运行良好。她正在使用 window 。
此错误出现在以下代码行之后(另请参阅屏幕截图):
acs <-
structure(list(`County Name` = c("U.S.", "Ohio", "Adams", "Allen",
"Ashland", "Ashtabula"), Year = c(2000, 2000, 2000, 2000, 2000,
2000), Sex = c("Male", "Male", "Male", "Male", "Male", "Male"
), `Age Group` = c("All", "All", "All", "All", "All", "All"),
`6th Grade or Less` = c(0.824, 0.038, 0.061, 0.012, 0.04,
0.031), `7th- 12th (No Diploma)` = c(0.085, 0.275, 0.343,
0.28, 0.283, 0.286), `High School Graduate` = c(0.037, 0.341,
0.347, 0.442, 0.436, 0.44), `Some College` = c(0.054, 0.171,
0.162, 0.149, 0.119, 0.148), `Bachelor's Degree` = c(NA,
0.097, 0.038, 0.067, 0.066, 0.053), `Graduate Degree` = c(NA,
0.077, 0.05, 0.049, 0.056, 0.041), `White Non-Hispanic` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Black Non-Hispanic` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Other Races Non-Hispanic in` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), Hispanic = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Total 60+` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Median Age for 60+` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% of Population Age 60 & Older` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% of Population` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% of Population Living Alone` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% of Grand Parents Living with Grand Children` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% of Population with High School Diploma or Higher Degree` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% of Population with College Degree` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Median Income` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% below 100% of Federal Povery Treshhold income` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% Medicaid Eligible` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `% employed` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Living Alone` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `0-100%` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `101-200%` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `201-300%` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `301-400%` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `>400%` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), Married = c(0.529,
0.752, 0.732, 0.774, 0.813, 0.724), `Widowed/Divorced/Separated` = c(0.168,
0.207, 0.22, 0.195, 0.153, 0.223), `Never Married` = c(0.303,
0.041, 0.047, 0.031, 0.034, 0.053), `At or Below Poverty Treshhold` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Above Four Times Poverty Treshhold` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Income to poverty_less 1` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Income to poverty_less 1-1.99` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Income to poverty_less 2-2.99` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Income to poverty_less 3-3.99` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_), `Income to poverty_less 4+` = c(NA_real_,
NA_real_, NA_real_, NA_real_, NA_real_, NA_real_)), row.names = c(NA,
-6L), class = c("tbl_df", "tbl", "data.frame"))
edu.county<-acs %>%
filter(Sex == "Total", `Age Group`=="All", `County Name`%in% c(county, "Ohio"), Year == max(acs$Year))
edu.county$`County Name`<-factor(edu.county$`County Name`, levels = c("Ohio", county))
edu.county<-edu.county %>%
select(`6th Grade or Less`, `7th- 12th (No Diploma)`, `High School Graduate`,
`Some College`, `Bachelor's Degree`, `Graduate Degree`) %>%
gather(c(`6th Grade or Less`, `7th- 12th (No Diploma)`, `High School Graduate`,
`Some College`, `Bachelor's Degree`, `Graduate Degree`), EduPerc)
County<-rep(c("Ohio", county), 6)
edu.county<-cbind(edu.county, County)
最佳答案
我认为违规者在以下两行:
gather(c(`6th Grade or Less`, `7th- 12th (No Diploma)`, `High School Graduate`,
`Some College`, `Bachelor's Degree`, `Graduate Degree`), EduPerc)
gather 需要一个以字符串形式给出的键和值列名称。您给它一个名称向量 (c(…))。这不起作用,并且不清楚您打算在这里做什么。您可能需要如下内容:
… gather(`Education level`, EduPerc) …
关于r - 错误 : Must supply a symbol or a string as argument,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/54407746/