我正在尝试读取 pdf 文件中表格的裁剪(手动)部分的一些统计信息。
Here is the image I'm trying to process
我得到的当前结果包含大部分数字但不是所有文本,如下所示:
{kind=link}
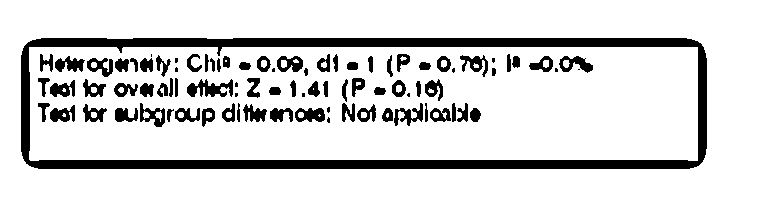
Hmuwinu'fg. cm’: -009,d1-I (F -o.761.l= .om,
Tamar wuall ma: 2 1.41(F-o.167
Tao! hr aubgrwp dimes: Nol wvwe
在调整大小步骤期间,我尝试使用除 inter-cubic 以外的插值,并尝试更改内核大小,但 1x1 似乎效果最好。
这是当前的代码:
# import the packages
from PIL import Image
import pytesseract
import numpy as np
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,help="path to input image to OCR'd")
ap.add_argument("-p","--preprocess",type=str,default="thresh",help="type of preprocessing to be done")
args = vars(ap.parse_args())
#load the example image
image = cv2.imread(args["image"])
# Rescale image
image = cv2.resize(image,None,fx=1.5,fy=1.5,interpolation=cv2.INTER_CUBIC)
#Apply dilation and erosion to remove some noise
kernel = np.ones((1,1),np.uint8)
image = cv2.dilate(image,kernel,iterations=1)
image = cv2.erode(image,kernel,iterations=1)
#Convert it to grayscale
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
# check to see if we should apply thresholding to process image
if args["preprocess"] == "thresh":
gray = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# make a check to see if median blurring should be applied
elif args["preprocess"] == "blur":
gray = cv2.medianBlur(gray,3)
#write the gray scale image to a disk as a temp file so we can OCR it
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename,gray)
#load the image as a PIL/pillow image, apploy OCR, then delete temp file
text = pytesseract.image_to_string(Image.open(filename))
os.remove(filename)
print(text)
# show the output images
cv2.imshow("Image",image)
cv2.imshow("Output",gray)
cv2.waitKey(0)
任何建议或方法都非常感谢。
最佳答案
我申请了 adaptive-threshold + bitwise-not操作和结果是:
现在,当我读到:
txt = pytesseract.image_to_string(bnt, config="--psm 6")
print(txt)
Hewrogenedty: Chit «0.09, die 1 (P = 0,78); If 0.0%
Teal for overall ettect: Z = 1.41 (P = 0.16)
Test tor subgroup ditlrenote: Not appliaalle
代码:
import cv2
import pytesseract
img = cv2.imread("Q8iIo.png")
img = cv2.resize(img, None, fx=2.5, fy=2.5,
interpolation=cv2.INTER_CUBIC)
gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
thr = cv2.adaptiveThreshold(gry, 255, cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY_INV, 25, 28)
bnt = cv2.bitwise_not(thr)
txt = pytesseract.image_to_string(bnt, config="--psm 6")
print(txt)
关于python - 用pytesseract读取低分辨率图像,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/53453921/