我正在解决分类问题。我为一组实体训练我的无监督神经网络(使用 skip-gram 架构)。
我评估的方法是从训练数据中为验证数据中的每个点搜索 k 个最近邻。我取最近邻居标签的加权总和(基于距离的权重),并使用每个验证数据点的分数。
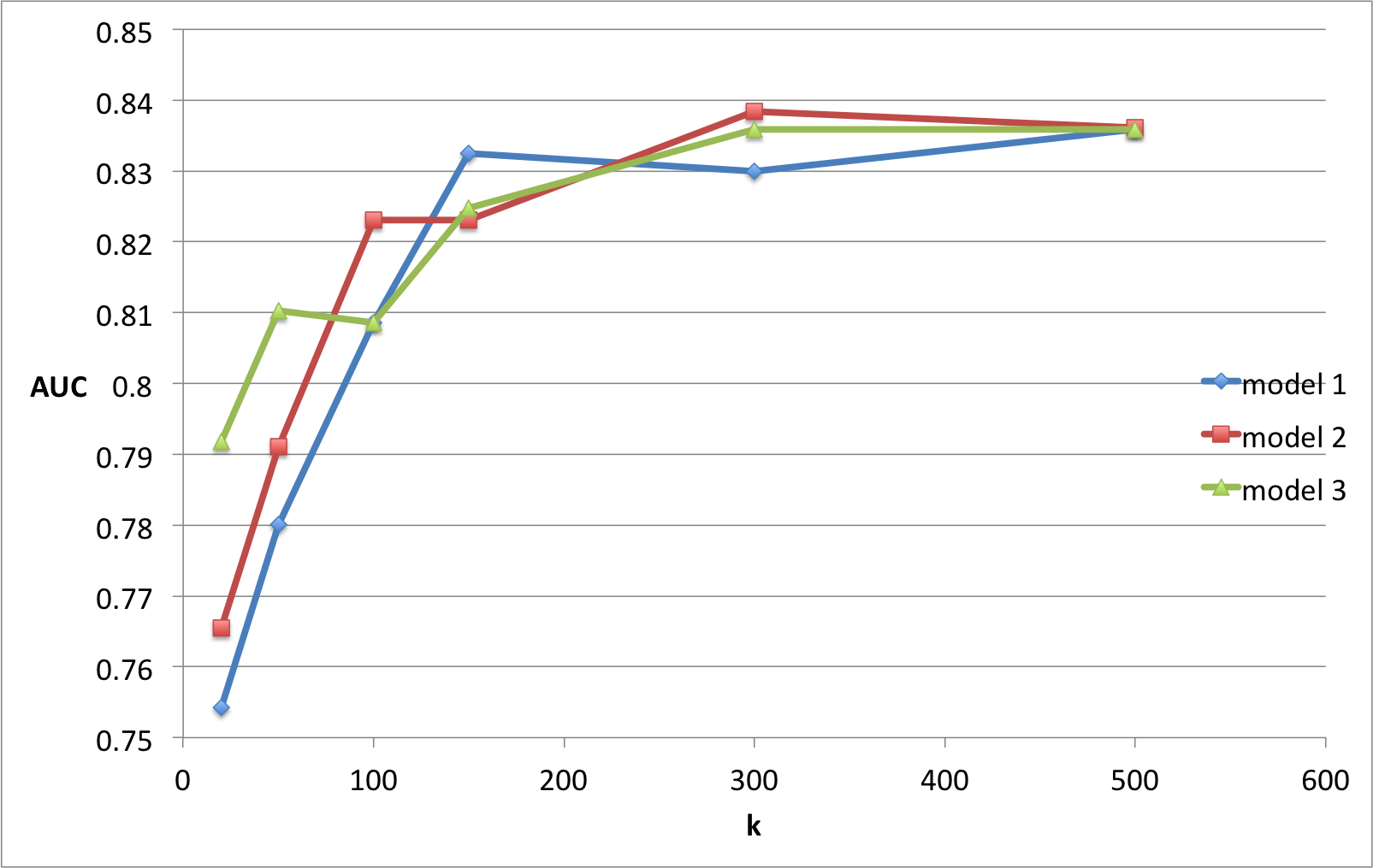
观察 - 随着我增加时代的数量(model1 - 600 个时代,model 2 - 1400 个时代和 model 3 - 2000 个时代),我的 AUC 在 k 的较小值下提高但在相似的值处饱和。
这种行为的可能解释是什么?
[Reposted来自交叉验证]
最佳答案
要交叉检查不平衡类是否是一个问题,请尝试拟合 SVM 模型。如果这提供了更好的分类(如果您的 ANN 不是很深,则可能),可以得出结论,应该首先平衡类。
另外,尝试一些核函数来检查这种转换是否使数据线性可分?
关于neural-network - 在 kNN 分类器中评估神经网络嵌入的性能,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/35218922/