我有这个示例 HTML,我想用 kuchiki 来解析它:
<a href="https://example.com"><em>@</em>Bananowy</a>
我只想要 Bananowy 而没有 @。
JavaScript 的类似问题:How to get the text node of an element?
最佳答案
首先,让我们从解析器如何解析开始:
<a href="https://example.com"><em>@</em>Bananowy</a>
进入一棵树。见下图:
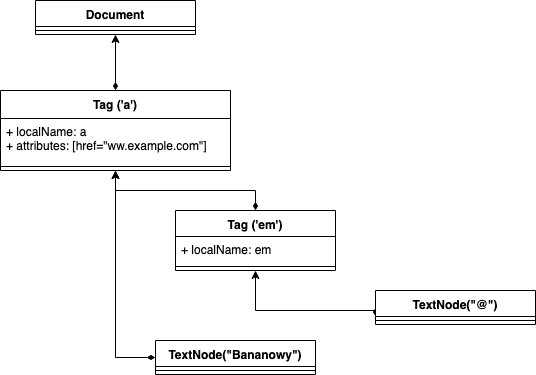
现在,如果您尝试做显而易见的事情并调用 anchor.text_contents()您将获得 anchor 标记 ( <a> ) 的所有文本节点后代的所有文本内容。这就是 text_contents 根据 CSS 定义的行为方式。
但是,您只想获取 "Bananowy"你有几种方法可以做到这一点:
extern crate kuchiki;
use kuchiki::traits::*;
fn main() {
let html = r"<a href='https://example.com'><em>@</em>Bananowy</a>";
let document = kuchiki::parse_html().one(html);
let selector = "a";
let anchor = document.select_first(selector).unwrap();
// Quick and dirty hack
let last_child = anchor.as_node().last_child().unwrap();
println!("{:?}", last_child.into_text_ref().unwrap());
// Iterating solution
for children in anchor.as_node().children() {
if let Some(a) = children.as_text() {
println!("{:?}", a);
}
}
// Iterating solution - Using `text_nodes()` iterators
anchor.as_node().children().text_nodes().for_each(|e| {
println!("{:?}", e);
});
// text1 and text2 are examples how to get `String`
let text1 = match anchor.as_node().children().text_nodes().last() {
Some(x) => x.as_node().text_contents(),
None => String::from(""),
};
let text2 = match anchor.as_node().children().text_nodes().last() {
Some(x) => x.borrow().clone(),
None => String::from(""),
};
}
第一种方法是脆弱的、hackish 的方法。您需要意识到的是"Bananowy"是last_child的 anchor 标记,并相应地获取它 anchor.as_node().last_child().unwrap().into_text_ref().unwrap() 。
第二个解决方案是迭代 anchor 标记的子级(即 [Tag(em), TextNode("Bananowy")] )并使用( as_text() 方法)仅选择文本节点。我们使用方法as_text()来做到这一点返回 None对于所有人Nodes那不是TextNode 。这比第一个解决方案要脆弱得多,如果例如你有<a><em>@</em>Banan<i>!</i>owy</a> .
编辑:
首选解决方案
环顾四周后,我发现了一个更好的解决方案来解决您的问题。它的名字叫TextNodes iterator 。
考虑到这一点,只需写 anchor.as_node().children().text_nodes().<<ITERATOR CODE GOES HERE>>;然后根据需要映射或操作条目。
为什么这个解决方案更好?它更简洁,它使用了老式的 Iterator所以它和你上面给出的JS答案非常相似。
关于rust - 如何使用 kuchiki 只获取 TEXT_NODE,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/56329121/