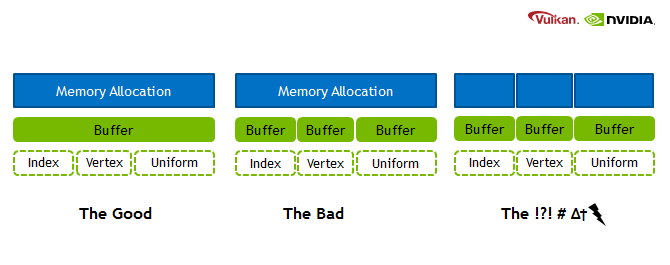
Vulkan 中推荐的内存管理方法是缓冲区的子分配,例如,请参见下图。
我正在尝试实现“好的”方法。我有一个系统可以告诉我内存分配中的哪些位置可用,因此我可以绑定(bind)单个大缓冲区的子区域。
但是,我找不到执行此操作的机制,或者只是误解了正在发生的事情,因为绑定(bind)函数将缓冲区作为输入和偏移量。除了通过现有缓冲区之外,我看不到如何指定绑定(bind)的大小。
所以我想我有几个问题:
我已经阅读了一些自定义分配器,但它们似乎遵循“坏”方法,将偏移量返回到大型分配中以进行绑定(bind),因此仍然有大量缓冲区但分配计数较低。
需要明确的是,除了通过 VMA 之外,我没有使用自定义分配器回调;我上面提到的“系统”位于 VMA 调用之上。
非常感谢任何指针!
最佳答案
are the dotted rectangles in the image below just bindings, or are they additional buffers?
它们代表实际数据。所以“索引” block 是包含顶点索引的存储范围。
if they are bindings, how do I tell Vulkan (ideally using VMA) to use that subsection of the buffer?
这取决于您如何使用
VkBuffer 的特殊性质。作为资源。一般来说,每个使用 VkBuffer 的函数因为资源需要一个字节偏移量,表示从哪里开始读取。许多此类函数还采用与偏移量相结合的大小,表示可以通过该特定资源读取的全部数据量。例如,
vkCmdBindVertexBuffers接受 VkBuffer 的数组s,并且对于每个 VkBuffer它还需要一个字节偏移量,表示该顶点缓冲区的起点。 VkDescriptorBufferInfo ,表示描述符使用的缓冲区的结构,采用 VkBuffer ,字节偏移量和大小。顶点缓冲区(和索引缓冲区)绑定(bind)没有大小,但它们不需要大小。它们的有效大小由与它们一起使用的渲染命令(以及它读取的索引数据)定义。如果您使用 100 个 32 位索引进行渲染,则预期索引缓冲区的大小减去起始偏移量后应至少为 400 字节。如果不是,UB 结果。
关于c++ - 如何在 Vulkan 中子分配缓冲区,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/65027692/