我需要编写如下解密函数的逆向(加密):
const crypto = require('crypto');
let AESDecrypt = (data, key) => {
const decoded = Buffer.from(data, 'binary');
const nonce = decoded.slice(0, 16);
const ciphertext = decoded.slice(16, decoded.length - 16);
const tag = decoded.slice(decoded.length - 16);
let decipher = crypto.createDecipheriv('aes-256-gcm', key, nonce);
decipher.setAuthTag(tag)
decipher.setAutoPadding(false);
try {
let plaintext = decipher.update(ciphertext, 'binary', 'binary');
plaintext += decipher.final('binary');
return Buffer.from(plaintext, 'binary');
} catch (ex) {
console.log('AES Decrypt Failed. Exception: ', ex);
throw ex;
}
}
上述函数允许我按照规范正确解密加密缓冲区:
| Nonce/IV (First 16 bytes) | Ciphertext | Authentication Tag (Last 16 bytes) |
AESDecrypt 之所以这样写(auth 标记为最后 16 个字节)是因为这就是 AES 的默认标准库实现在 Java 和 Go 中加密数据的方式。我需要能够在 Go、Java 和 Node.js 之间双向解密/加密。 Node.js 中基于 crypto 库的加密不会将 auth 标记放在任何地方,开发人员希望如何存储它以传递给 setAuthTag()在解密过程中。在上面的代码中,我将标签直接烘焙到最终的加密缓冲区中。
因此我编写的 AES 加密函数需要满足上述情况(无需修改 AESDecrypt 因为它可以正常工作)并且我有以下代码不适合我:
let AESEncrypt = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Do not copy paste this line in production code (https://crypto.stackexchange.com/questions/26790/how-bad-it-is-using-the-same-iv-twice-with-aes-gcm)
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
try {
let encrypted = nonce;
encrypted += cipher.update(encoded, 'binary', 'binary')
encrypted += cipher.final('binary');
const tag = cipher.getAuthTag();
encrypted += tag;
return Buffer.from(encrypted, 'binary');
} catch (ex) {
console.log('AES Encrypt Failed. Exception: ', ex);
throw ex;
}
}
我知道对 nonce 进行硬编码是不安全的。我通过这种方式可以更轻松地使用像 vbindiff 这样的二进制文件差异程序将正确加密的文件与我损坏的实现进行比较。
我从不同的角度看待这个问题的次数越多,这个问题对我来说就越令人困惑。
我实际上非常习惯于实现基于 256 位 AES GCM 的加密/解密,并且在 Go 和 Java 中有正常工作的实现。此外,由于某些情况,几个月前我在 Node.js 中实现了 AES 解密的工作。
我知道这是真的,因为我可以在 Node.js 中解密我用 Java 和 Go 加密的文件。我建立了一个快速存储库,其中包含专为此目的编写的 Go 服务器的源代码实现和损坏的 Node.js 代码。
为了便于了解 Node.js 但不了解 Go 的人访问,我提供了以下 Go 服务器 Web 界面,使用托管在 https://go-aes.voiceit.io/ 的上述算法进行加密和解密。 .您可以通过在 https://go-aes.voiceit.io/ 加密您选择的文件来确认我的 Node.js 解密功能工作正常, 并使用 decrypt.js 解密文件(如果您需要确认它是否正常工作,请查看 README 以获取有关如何运行它的更多信息。)
此外,我知道这个问题特别与以下 AESEncrypt 行有关:
const tag = cipher.getAuthTag();
encrypted += tag;
正在运行 vbindiff针对在 Go 和 Node.js 中加密的同一文件,这些文件仅在最后 16 个字节(写入 auth 标记的位置)开始显示差异。换句话说,随机数和加密的有效负载在 Go 和 Node.js 中是相同的。
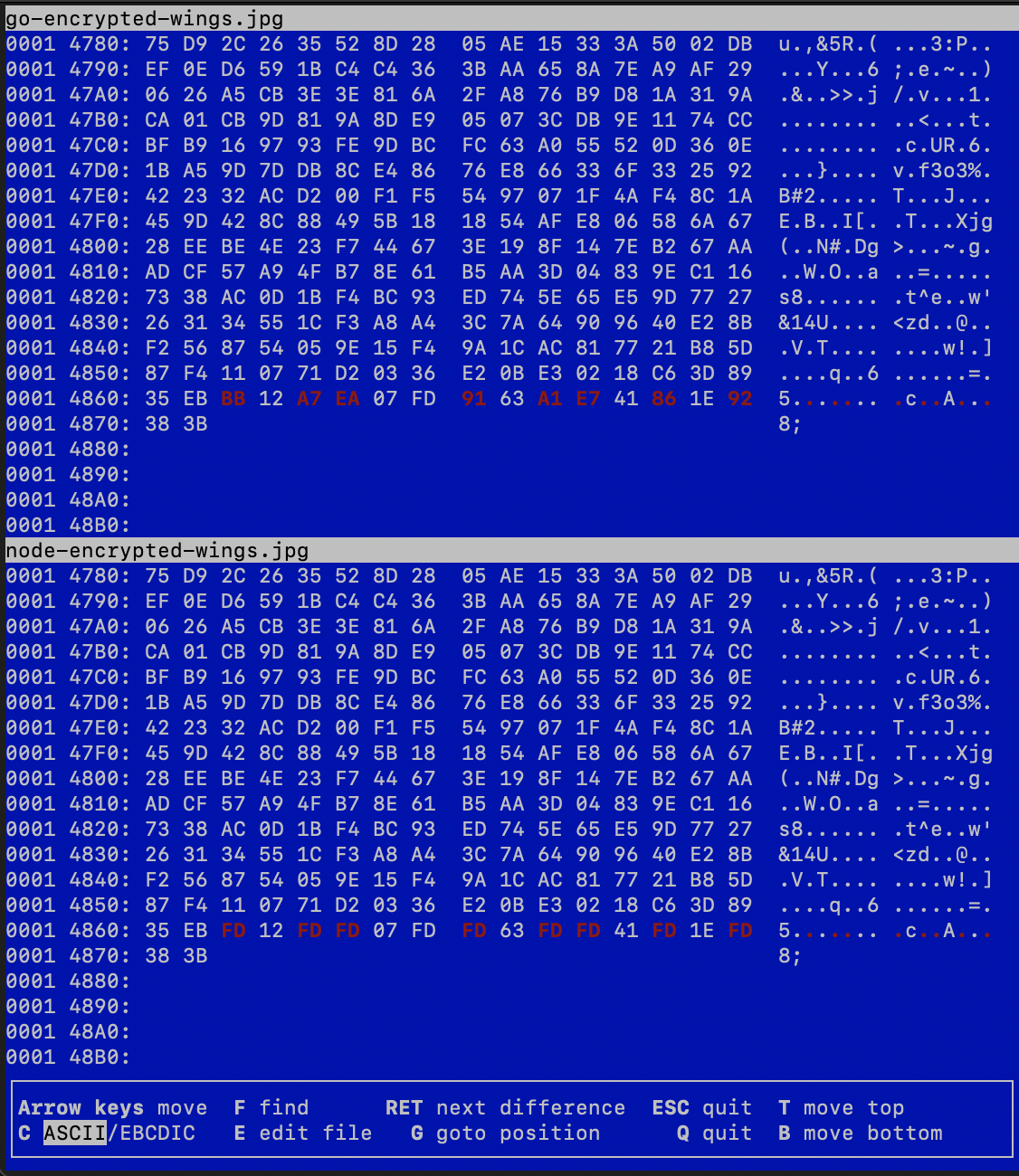
由于 getAuthTag() 非常简单,而且我相信我正在正确使用它,所以我不知道此时我什至可以更改什么。因此,我也考虑了这是标准库中的错误的可能性很小。但是,我认为在发布 Github Issue 之前我应该先尝试 Stackoverflow,因为这很可能是我做错的事情。
我在 repo 中对代码进行了更详细的描述,并证明了我如何知道什么是有效的。我设置尝试获得解决此问题的帮助。
提前谢谢你。
更多信息: Node :v14.15.4 Go:go version go1.15.6 darwin/amd64
最佳答案
在 NodeJS 代码中,密文生成为 binary string ,即使用 binary/latin1 或 ISO-8859-1 编码。 ISO-8859-1 是一个单字节字符集,它将 0x00 和 0xFF 之间的每个值唯一地分配给特定字符,因此允许将任意二进制数据转换为字符串而不会损坏,另请参见 here 。
相比之下,cipher.getAuthTag() 不会将身份验证标记作为二进制字符串返回,而是作为缓冲区返回。
当连接两个部分时:
encrypted += tag;
缓冲区使用 buf.toString() 隐式转换为字符串,默认情况下应用 UTF-8 编码。
与 ISO-8859-1 不同,UTF-8 是一个多字节字符集,它定义了分配给字符 s 的 1 到 4 个字节长度的特定字节序列。 UTF-8 table 。在任意二进制数据(例如身份验证标签)中,通常存在未针对 UTF-8 定义的字节序列,因此无效。在转换期间,无效字节由代码点为 U+FFFD 的 Unicode 替换字符表示(另请参阅@dave_thompson_085 的评论)。这会破坏数据,因为原始值会丢失。因此 UTF-8 编码不适合将任意二进制数据转换为字符串。
在随后转换为具有单字节 charset binary/latin1 的缓冲区时:
return Buffer.from(encrypted, 'binary');
仅考虑替换字符的最后一个字节 (0xFD)。
截图中标记的字节(0xBB、0xA7、0xEA等)都是无效的UTF-8字节序列,s。 UTF-8 table ,因此被 0xFD 的 NodeJS 代码替换,导致标签损坏。
为了修复这个bug,tag必须用binary/latin1转换,即和密文的编码一致:
let AESEncrypt = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Static IV for test purposes only
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
let encrypted = nonce;
encrypted += cipher.update(encoded, 'binary', 'binary');
encrypted += cipher.final('binary');
const tag = cipher.getAuthTag().toString('binary'); // Fix: Decode with binary/latin1!
encrypted += tag;
return Buffer.from(encrypted, 'binary');
}
请注意,在 update() 调用中,输入编码(第二个 'binary' 参数)被忽略,因为 encoded 是缓冲区。
或者,可以连接缓冲区而不是二进制/latin1 转换字符串:
let AESEncrypt_withBuffer = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Static IV for test purposes only
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
return Buffer.concat([ // Fix: Concatenate buffers!
Buffer.from(nonce, 'binary'),
cipher.update(encoded),
cipher.final(),
cipher.getAuthTag()
]);
}
对于 GCM 模式,出于性能和兼容性原因,NIST 建议使用 12 字节的随机数长度,请参见 here, chapter 5.2.1.1 和 here 。 Go 代码(通过 NewGCMWithNonceSize())和 NodeJS 代码应用与此不同的 16 字节长度的随机数。
关于node.js - 在 Node.js 中获取 256 位 AES GCM 加密的正确标签时遇到问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/65639698/