我正在阅读一本有关Elasticsearch的书,但是对我来说尚不清楚,尝试查看文档(并没有真正谈论其架构),但是其他帖子似乎找不到相关的帖子。
说我有一个文件如下:{message: "hello world Welcome to Elastic"}
所以现在每个术语分散在不同的碎片上吗?
在书中,它说:“如果在分布式环境中创建elasticsearch,则可以将一个索引分布到不同的节点中”。这是否意味着属于index1的分片子集存储在另一个索引中?
最佳答案
由于一幅图片值(value)一千个单词,因此以下图片很好地说明了Elasticsearch的分布式性质。
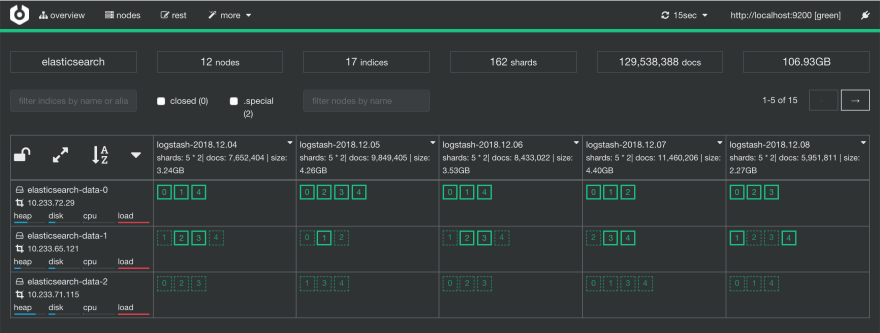
所以主要的收获是:
logstash-*列)elasticsearch-*行)关于elasticsearch - Elasticsearch,当文档存储时,它会分成不同的碎片吗?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/59064364/