我正在尝试使用我的 Hadoop 多节点集群:
- 1 个名称节点(主节点)
- 2 个数据节点(slave1 和 slave2)
我想用 MapReduce 做一些测试,但我遇到了一个问题,我找不到解决这个问题的地方。
我向我的 HDFS 上传了一个名为 data.txt 的文件
我创建了两个文件:mapper.py 和 reducer.py,它们存储在我的 hadoop 本地存储库中。
我执行了这个命令:
hadoop jar /usr/local/hadoop-2.7.5/share/hadoop/tools/lib/hadoop-streaming-2.7.5.jar
-mapper /usr/local/hadoop/mapper.py -reducer /usr/local/hadoop/reducer.py
-input hdfs://master:54310/data.txt -output hdfs://master:54310/output.txt
在我的终端中,我遇到了这个问题:
packageJobJar: [/tmp/hadoop-unjar6386556681700293769/] [] /tmp/streamjob2613722562503212451.jar tmpDir=null
18/03/16 15:45:02 INFO client.RMProxy: Connecting to ResourceManager at master/172.30.10.64:8050
18/03/16 15:45:03 INFO client.RMProxy: Connecting to ResourceManager at master/172.30.10.64:8050
18/03/16 15:45:05 INFO mapred.FileInputFormat: Total input paths to process : 1
18/03/16 15:45:05 INFO mapreduce.JobSubmitter: number of splits:2
18/03/16 15:45:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1521211085961_0001
18/03/16 15:45:06 INFO impl.YarnClientImpl: Submitted application application_1521211085961_0001
18/03/16 15:45:06 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1521211085961_0001/
18/03/16 15:45:06 INFO mapreduce.Job: Running job: job_1521211085961_0001
18/03/16 15:45:21 INFO mapreduce.Job: Job job_1521211085961_0001 running in uber mode : false
18/03/16 15:45:21 INFO mapreduce.Job: map 0% reduce 0%
18/03/16 15:45:39 INFO mapreduce.Job: Task Id : attempt_1521211085961_0001_m_000001_0, Status : FAILED
Error: java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:112)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:78)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:136)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:450)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:109)
... 9 more
Caused by: java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:112)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:78)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:136)
at org.apache.hadoop.mapred.MapRunner.configure(MapRunner.java:38)
... 14 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:109)
... 17 more
Caused by: java.lang.RuntimeException: configuration exception
at org.apache.hadoop.streaming.PipeMapRed.configure(PipeMapRed.java:222)
at org.apache.hadoop.streaming.PipeMapper.configure(PipeMapper.java:66)
... 22 more
Caused by: java.io.IOException: Cannot run program "/usr/local/hadoop/mapper.py": error=2, Aucun fichier ou dossier de ce type
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048)
at org.apache.hadoop.streaming.PipeMapRed.configure(PipeMapRed.java:209)
... 23 more
Caused by: java.io.IOException: error=2, Aucun fichier ou dossier de ce type
at java.lang.UNIXProcess.forkAndExec(Native Method)
at java.lang.UNIXProcess.<init>(UNIXProcess.java:247)
at java.lang.ProcessImpl.start(ProcessImpl.java:134)
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1029)
... 24 more
18/03/16 15:45:39 INFO mapreduce.Job: Task Id : attempt_1521211085961_0001_m_000000_0, Status : FAILED
Error: java.lang.RuntimeException: Error in configuring object
所以我查看了:http://172.30.10.64:8088/proxy/application_1521211085961_0001/
HTTP ERROR 500
Problem accessing /proxy/application_1521211085961_0001/. Reason:
Connection to http://slave1:8088 refused
Caused by:
org.apache.http.conn.HttpHostConnectException: Connection to http://slave1:8088 refused
这很奇怪,因为我的两个数据节点都配置良好(我可以 ping,我可以通过 ssh 连接,...)
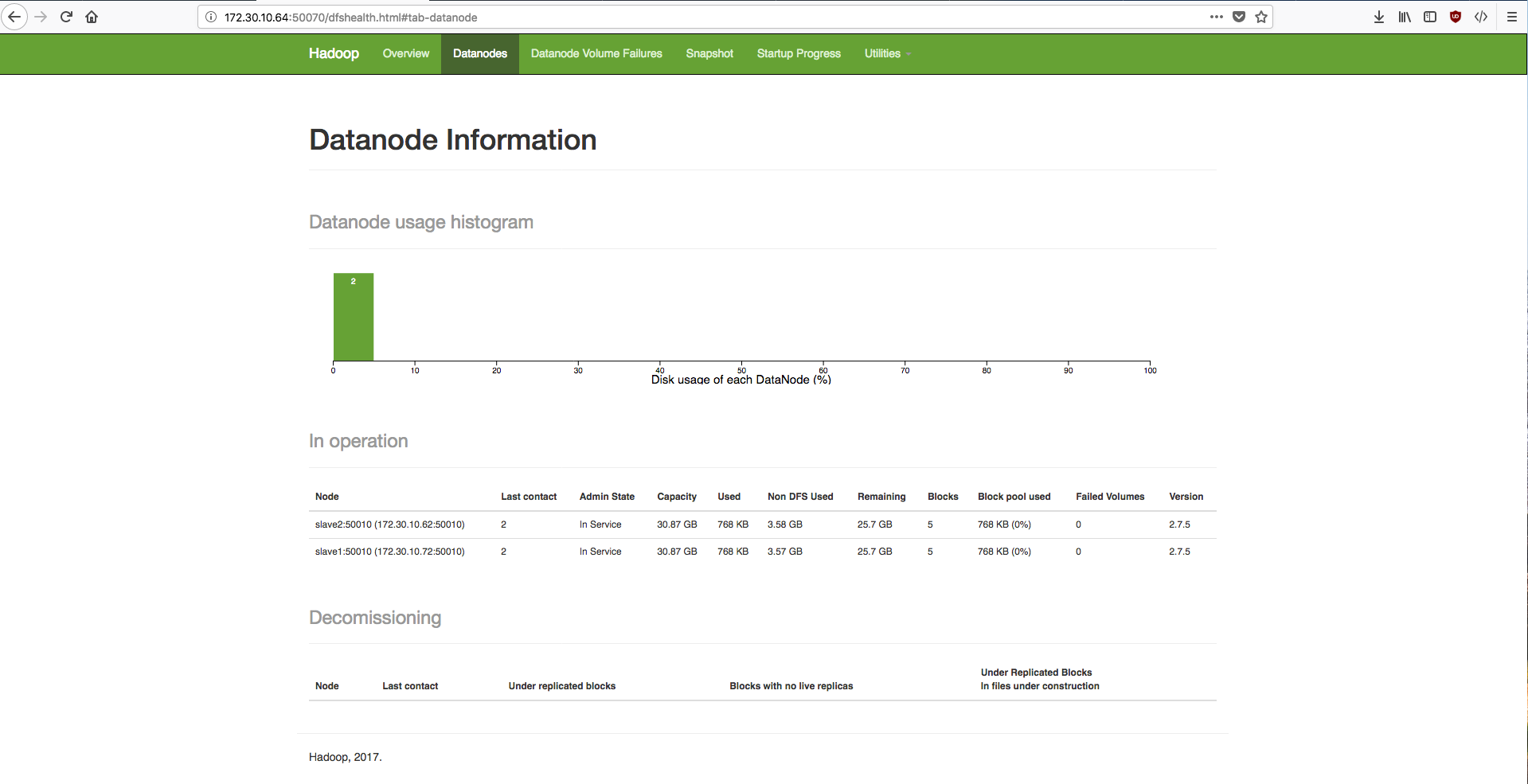
我的配置:
第一步:
/etc/hosts 在每个节点上都很好:
- 172.30.10.64 主人
- 172.30.10.72 slave1
- 172.30.10.62 slave2
第二步:
/etc/hostname 在每个节点上都很好:
- 主节点的master
- slave1为slave1节点
- slave2为slave2节点
第三步:
命令 jps 在主节点上给我:
4131 NameNode
4501 ResourceManager
5049 Jps
4347 SecondaryNameNode
在从节点上:
2357 DataNode
2491 NodeManager
2957 Jps
那么为什么我的 namenode 被拒绝连接到 slave1 呢?
编辑:
我 2 年前在 Proxmox 上使用 3 个虚拟机安装了 Hadoop,以模拟每个节点,并且启用了 NAT 模式。
现在,我正在使用 VMWare VSphere,但我没有 NAT 模式。
我的问题可能来自这个选项 ??
最佳答案
从您的 jps 输出中,我发现主服务器上没有 JobTracker,从服务器上也没有 TaskTracker。我认为您可能忘记了在您的主机上运行 bin/start-mapred.sh,如果您已经运行过它,那么我认为您需要在您的从机上检查/提供日志/hadoop-hduser-tasktracker-slave.log 以查找错误. 另请查看此 post用于设置 hadoop 多节点集群 一步一步。
关于Hadoop 多节点集群 : Connection failed with slave node,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/49323958/