我的语法学习曲线很陡,我的数据有PII,所以我不知道如何描述。
在已经建立索引的文档中,我需要在kibana中添加一个新字段。此字段“C”将是字段“A”的前4位数字的组合,该字段包含数以百万计且类型为:keyword的数字,以及字段“B”类型为:keyword且为某个大数字。
稍后,我将使用此字段“C”(它是唯一的组合)与项目列表/数组进行比较(我将列表插入Kibana的查询DSL中,因为我需要使用返回的文档构建一些可视化和报告)。
我看到我可以不费力地创建这个新字段,但是我不知道我是否需要使用正则表达式以及如何使用它。
编辑:
根据要求,提供了有关具体示例的更多信息。
"fieldA" : {
"type: "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"fieldB" : {
"type: "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
FieldA =“9876443320134”,
FieldB =“000000001”。
我想对FieldA的前4位数字和FieldB的全部内容求和。 FieldC的结果将为“9877”。
最佳答案
原始查询可能如下所示:
GET combination_index/_search
{
"script_fields": {
"a+b": {
"script": {
"source": """
def a = doc['fieldA.keyword'].value;
def b = doc['fieldB.keyword'].value;
if (a == null || b == null) {
return null
}
def parsed_a = new BigInteger(a);
def parsed_b = new BigInteger(b);
return new BigInteger(parsed_a.toString().substring(0, 4)) + parsed_b;
"""
}
}
}
}
BigInteger似乎不足的Integer.MAX_VALUE b / c。注意2:我们首先解析
fieldA,然后再对其再次调用.toString,以便处理从零开始以fieldA开头的009876443320134的边缘情况。假设您要查找的是9876而不是98,这是首先调用.substring然后进行解析的结果。如果打算在Kibana可视化中使用它,则首先需要一个索引模式。一旦获得一个,您可以按照以下步骤进行:
然后将脚本放入:
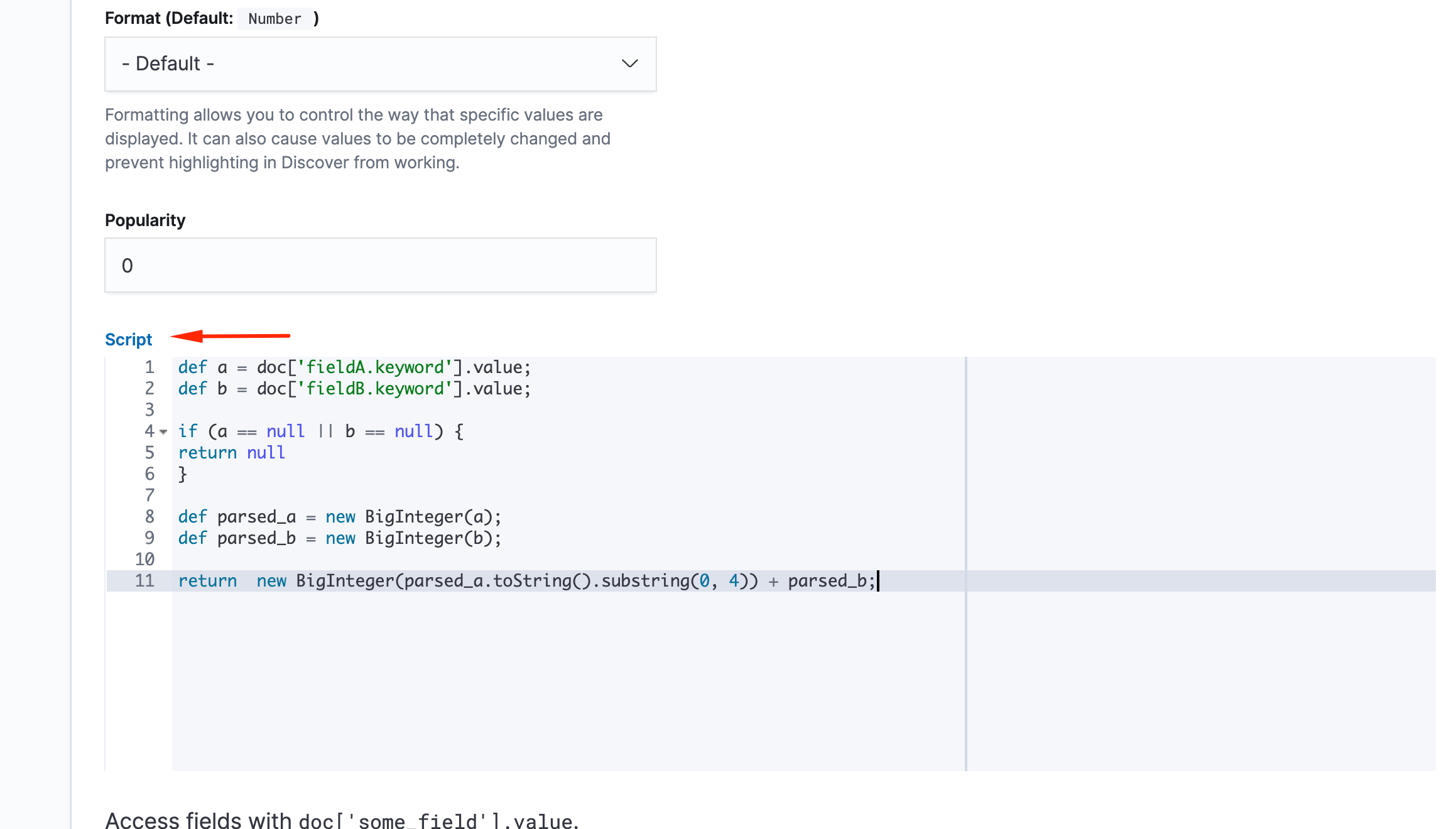
单击保存,新的脚本就可以在数字聚合和查询中使用:

关于elasticsearch - 如何在Kibana中编写与字段的前4位数字匹配的字段的脚本?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/64597516/