Hadoop 新手,我想了解 Hadoop 如何读取文件输入:我能够使用下面的代码从 2 列(键/值)输入文件运行 Hadoop 作业:
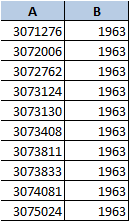
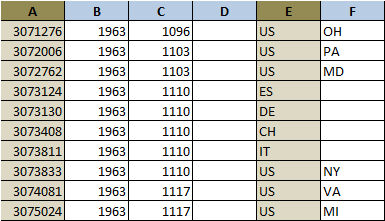
但是如果我有 5 列并且我想要的(键/值)是 A&E(而不是 A&B)我需要准确修改哪个函数呢?
public class InverterCounter extends Configured implements Tool {
public static class MapClass extends MapReduceBase
implements Mapper<Text, Text, Text, Text> {
public void map(Text key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException {
output.collect(value, key);
}
}
public static class Reduce extends MapReduceBase
implements Reducer<Text, Text, Text, IntWritable> {
public void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int count = 0;
while (values.hasNext()) {
values.next();
count++;
}
output.collect(key, new IntWritable(count));
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, InverterCounter.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("InverterCounter");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(KeyValueTextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.set("key.value.separator.in.input.line", ",");
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new InverterCounter(), args);
System.exit(res);
}
}
如果有任何建议,我将不胜感激,我正在尝试更改 job.set("key.value.separator.in.input.line", ","); 和 job.setInputFormat (KeyValueTextInputFormat.class); 运气不好仍然无法解决这个问题。
谢谢
最佳答案
KeyValueTextInputFormat 假定键位于每行的开头,因此它不适用于您的 6 列数据集。
相反,您可以使用 TextInputFormat并提取 key 并为自己赋值。我假设该行中的所有值都用逗号分隔(并且数据中没有逗号,这是另一回事)。
使用 TextInputFormat,您会在 value 中收到完整的行,并在 key 中收到该行在文件中的位置。我们不需要这个位置,所以我们会忽略它。通过单个 Text 中的完整行,我们可以将其转换为 String,用逗号分隔,并导出要发出的键和值:
public class InverterCounter extends Configured implements Tool {
public static class MapClass extends MapReduceBase
implements Mapper<Text, Text, Text, Text> {
public void map(Text key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException {
String[] lineFields = value.toString().split(",");
Text outputKey = new Text(lineFields[0] + "," + lineFields[4]);
Text outputValue = new Text(lineFields[1] + "," + lineFields[2] + "," +
lineFields[3] + "," + lineFields[5]);
output.collect(outputKey, outputValue);
}
}
public static class Reduce extends MapReduceBase
implements Reducer<Text, Text, Text, IntWritable> {
public void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int count = 0;
while (values.hasNext()) {
values.next();
count++;
}
output.collect(key, new IntWritable(count));
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, InverterCounter.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("InverterCounter");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new InverterCounter(), args);
System.exit(res);
}
}
我还没有机会测试这个,所以可能会有小错误。您可能想要重命名该类,因为它不再反转任何东西。最后,该值已发送到 reducer 但未被使用,因此您可以轻松发送 NullWritable。相反。
关于java - 如何为 map reducer 作业在 java 中为 hadoop 输入自定义选择列读取,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/29050370/