大家,
我对通过智能IDEA运行spark有疑问。如果有人可以为我提供帮助,我将非常感谢。非常感谢。我用谷歌搜索,尝试过,但是什么也没做,甚至使结果更糟,所以我只保留原始内容。
我输入了一些简单的scala代码来测试通过intelliJ IDEA运行的spark,但是出现了一些错误。我的问题在这里:
1.请看图片1&2。有2个错误“无法
解析符号===“并且“值'$'不是StringConext的成员”,
详细信息在图3中。
2.如果我用“//”注释了错误的代码行,则代码可以运行,可以读取并显示df,但是计算平均值的代码行无效。错误显示在图片4和5中。
谁能帮助我解决这两个问题。非常感谢!!!
demo
pom.xml
error1
error2
final result
这是我的pom.xml代码:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.test.demo</groupId>
<artifactId>DemoProject</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>apache</id>
<url>http://maven.apache.org</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
</project>
这是我的scala case对象的代码:
import org.apache.spark.sql.SparkSession
import java.io.File
import org.apache.spark
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
object Demo {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Spark SQL basic example")
.getOrCreate()
val peopleDFCsv = spark.read.format("csv")
.option("sep", "\t")
.option("header", "false")
.load("C:\\Users\\shell\\OneDrive\\Desktop\\marks.csv")
peopleDFCsv.printSchema()
peopleDFCsv.show(15)
val df = spark.read.option("inferScheme", "true").option("header", "true").csv("C:\\Users\\shell\\OneDrive\\Desktop\\marks.csv")
df.show()
df.withColumn("id", monotonically_increasing_id()).show
df.join(df.groupBy("max(marks)"), $"marks" === $"max(marks)", "leftsemi").show
df.join(df.filter("subject = maths").groupBy("max(marks)"). $"marks" === $"max(marks)", "leftsemi").show
df.join(df.filter("subject = maths").select(mean(df("marks")))).show
// val a = new File("./data").listFiles()
// a.foreach(file => println(file.getPath))
}
}
最佳答案
因此,联接函数错误的第一个原因是错误的参数。在您的第一个联接函数中,groupBy将返回RelationalGroupedDataset而不是Dataframe。您需要在groupBy函数之后聚合一些东西。看我的例子。要在列名中使用$,您需要import spark.implicits._。另外,您需要import org.apache.spark.sql.functions._才能使用标准的spark列函数,请看:
import spark.implicits._
import org.apache.spark.sql.functions._
import java.io.File
val df = spark.read.option("inferScheme", "true").option("header", "true").csv("C:\\Users\\shell\\OneDrive\\Desktop\\marks.csv")
df.show()
// df.withColumn("id", monotonically_increasing_id()).show
df.join(df.groupBy("column_for_group").agg(max("marks")), $"marks" === max($"marks"), "leftsemi").show
df.join(df.filter("subject = maths").groupBy("column_for_group").agg(max("marks")), $"marks" === max($"marks"), "leftsemi").show
df.join(df.filter("subject = maths").select(mean(df("marks")))).show
val a = new File("./data").listFiles()
a.foreach(file => println(file.getPath))
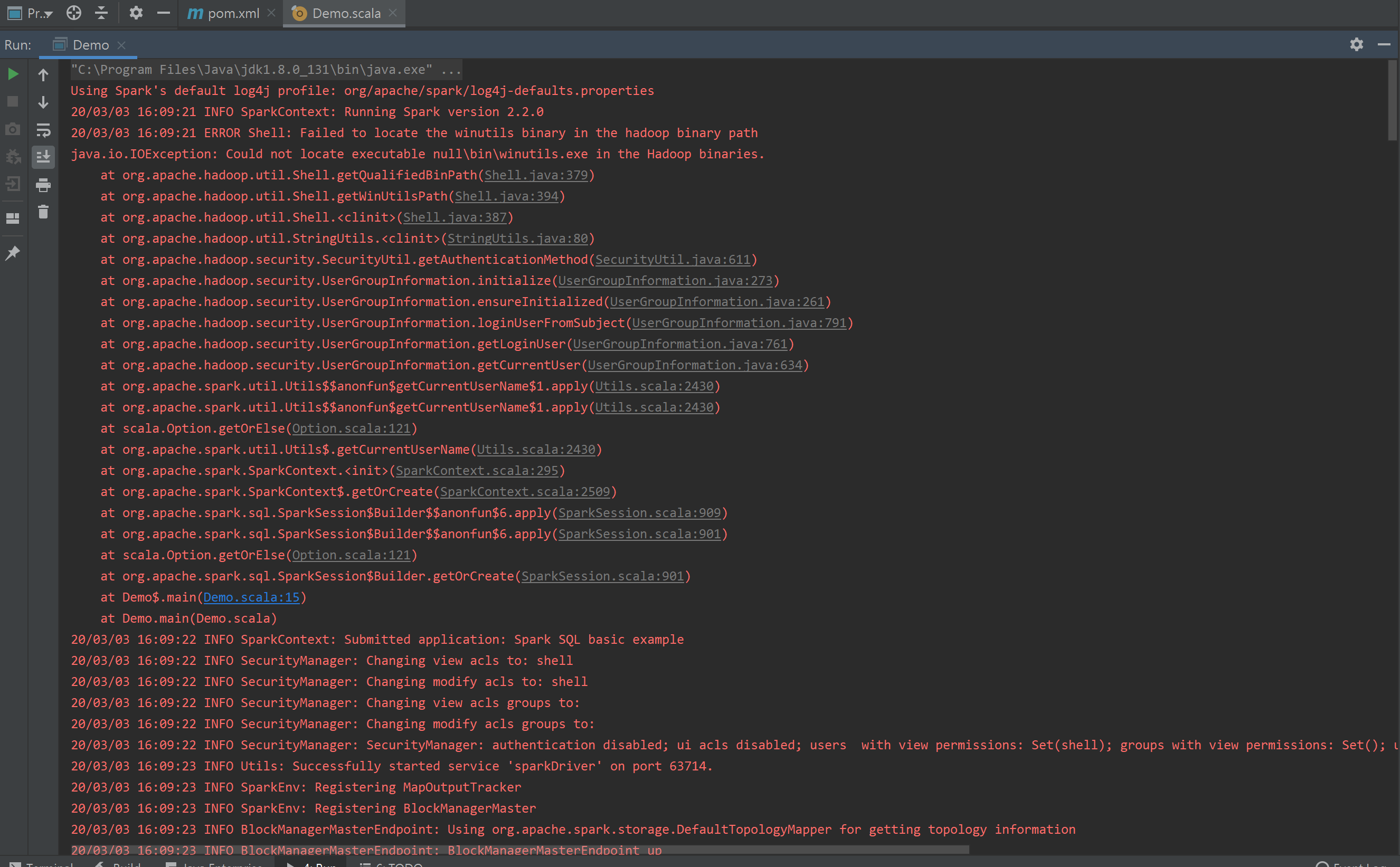
可以通过设置正确的环境变量来解决winutils的错误。您需要用googlet之类的
windows 10 how set environment variable进行搜索。最好在系统中而不是通过编程来完成。
关于scala - intelliJ运行中的 Spark :无法解析符号和标识符,但找到了字符串,并找到了 ';',但找到了 ')',我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/60511843/