我正在尝试使用Hadoop MapReduce找到值列表的Min和Max,这是我实现Reduce代码的方式:
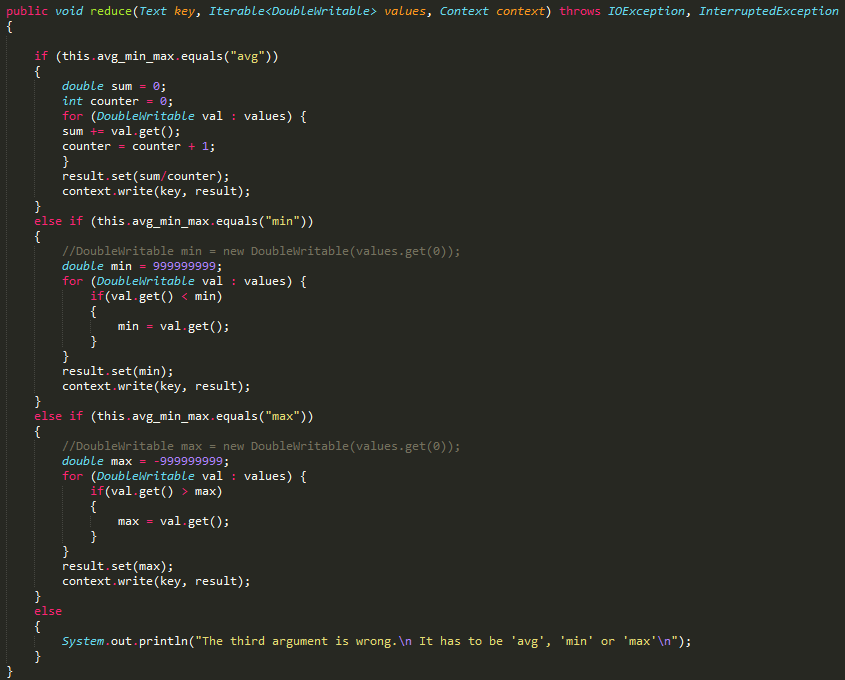
如您所见,我对计算"avg"没问题,但是对于"min"和"max",我知道正确的方法是分配min = "first element of the Iterable<DoubleWritable>"和max = "first element of the Iterable<DoubleWritable>"。我尝试了已经被注释掉的代码,但是它们没有用。因此,我将min和max临时分配给一个很大和非常小的数字。
如果有人能教我如何访问Iterable<DoubleWritable>的第一个元素,并在这种情况下将其分配给“min”和“max”,我将非常感谢。为了方便您引用,我还将代码粘贴在这里:
public void reduce(Text key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException
{
if (this.avg_min_max.equals("avg"))
{
double sum = 0;
int counter = 0;
for (DoubleWritable val : values) {
sum += val.get();
counter = counter + 1;
}
result.set(sum/counter);
context.write(key, result);
}
else if (this.avg_min_max.equals("min"))
{
//DoubleWritable min = new DoubleWritable(values.get(0));
double min = 999999999;
for (DoubleWritable val : values) {
if(val.get() < min)
{
min = val.get();
}
}
result.set(min);
context.write(key, result);
}
else if (this.avg_min_max.equals("max"))
{
//DoubleWritable max = new DoubleWritable(values.get(0));
double max = -999999999;
for (DoubleWritable val : values) {
if(val.get() > max)
{
max = val.get();
}
}
result.set(max);
context.write(key, result);
}
else
{
System.out.println("The third argument is wrong.\n It has to be 'avg', 'min' or 'max'\n");
}
}
最佳答案
实际上,最安全,最快的方法是对最大数使用-Double.MAX_VALUE,对最小数使用Double.MAX_VALUE,因为您不需要两次获取迭代器。
但是,如果仍然要使用第一个元素,则可以这样使用:
double max = values.iterator().next().get();
关于java - 如何使用JAVA访问Hadoop MapReduce中Iterable <DoubleWritable>的第一个元素?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/40961416/