当我将 reducer 的数量设置为零时,映射阶段完成得非常快(约 10 分钟)。 但是,当我将 reducer 的数量设置为大于 1 时,映射阶段所需的时间(完全相同的映射器代码)会急剧增加(我在大约 30 分钟后停止,而它仍然是 20%)。队列中的第一个 map 任务达到 100%,然后进程卡住。
有什么直觉吗?是不是当没有使用 reducer 时,map 输出直接进入磁盘,而当使用 reduce 阶段时,map 输出进入内存缓冲区?
我的主映射器循环的伪代码如下:
for (VIntWritable e1 : D2entities) {
for (VIntWritable e1 : D1entities) {
output.collect(e1, e2);
}
}
在这两种情况下,我都使用 conf.setCompressMapOutput(true) 和 conf.set("mapred.reduce.slowstart.completed.maps", "1.00"); .当我使用 reducer 时,我还设置了:
conf.setOutputKeyClass(VIntWritable.class);
conf.setOutputValueClass(NullWritable.class);
conf.setMapOutputKeyClass(VIntWritable.class);
conf.setMapOutputValueClass(VIntWritable.class);
否则,我使用:
conf.setOutputKeyClass(VIntWritable.class);
conf.setOutputValueClass(VIntWritable.class);
最佳答案
当你将 reducer 的数量设置为 0 时,你正在做一个只有 map 的工作。这意味着数据不会被排序或打乱,映射器的输出将直接写入磁盘。但是,如果你使用 reducer,那么你有两种情况:当你只需要对数据进行排序时,当你还需要对数据执行一些聚合或一些操作时。
如果您只需要对数据进行排序,您可以使用 identity reducer,它将对数据进行排序,执行混洗,将其提供给 reducer,然后将其写入磁盘。在第二种情况下,reducer 需要额外的时间来执行您希望执行的操作,无论是聚合还是任何其他操作。
所以是的,在只做 map 工作和写 reduce 阶段的时间上有很大的不同。考虑下图,如果在映射后直接将其写入磁盘,则无需执行所有步骤:

编辑:当添加一个 reduce 阶段时,您会看到映射器达到 100% 但没有显示为已完成,因为出于效率原因在映射阶段进行了一些预排序,也使得一些缓冲写入内存。因此,当您仅将工作编写为 map 时,这并没有完成,而且完成得更快。但是,既然您还使用了 reducer,一旦它达到 100% 的映射器,它就会开始在内存中进行预排序和缓冲,直到完成后才会显示为“已完成”。
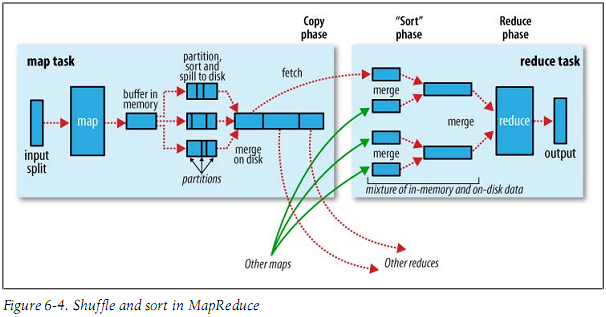
希望现在更清楚了!
关于hadoop - 使用 reducer 会减慢映射器,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/25012337/