我正在使用带有自定义分隔符的 SparkContext.newAPIHadoopFile 读取多行记录文件。反正我已经做好了准备,减少了我的数据。但现在我想再次将 key 添加到每一行(条目),然后将其写入 Apache Parquet 文件,然后将其存储到 HDFS 中。
这个图应该可以解释我的问题。我正在寻找的是红色箭头,例如写入文件之前的最后一次转换。任何想法?我尝试了 flatMap,但时间戳和浮点值导致了不同的记录。
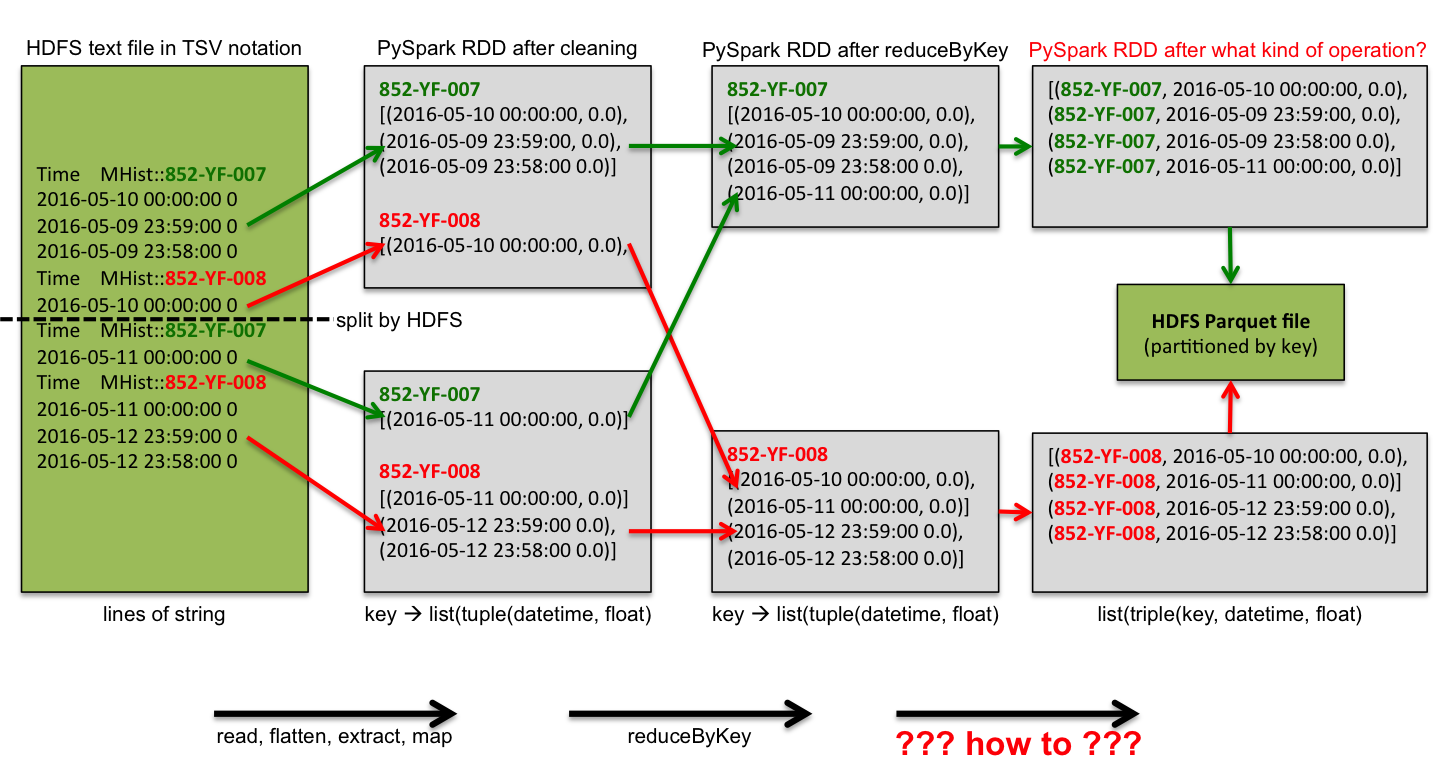
Python 脚本可以是 downloaded here和样本text file here 。我在 Jupyter Notebook 中使用 Python 代码。
最佳答案
简单的列表理解应该足够了:
from datetime import datetime
def flatten(kvs):
"""
>>> kvs = ("852-YF-008", [
... (datetime(2016, 5, 10, 0, 0), 0.0),
... (datetime(2016, 5, 9, 23, 59), 0.0)])
>>> flat = flatten(kvs)
>>> len(flat)
2
>>> flat[0]
('852-YF-008', datetime.datetime(2016, 5, 10, 0, 0), 0.0)
"""
k, vs = kvs
return [(k, v1, v2) for v1, v2 in vs]
在 Python 2.7 中,您还可以使用带有元组参数解包的 lambda 表达式,但这不可移植并且通常不鼓励:
lambda (k, vs): [(k, v1, v2) for v1, v2 in vs]
版本无关:
lambda kvs: [(kvs[0], v1, v2) for v1, v2 in kvs[1]]
编辑:
如果您需要的只是写入分区数据,则直接转换为 Parquet,无需 reduceByKey:
(sheet
.flatMap(process)
.map(lambda x: (x[0], ) + x[1])
.toDF(["key", "datettime", "value"])
.write
.partitionBy("key")
.parquet(output_path))
关于python - PySpark(Python 2.7): How to flatten values after reduce,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/38140710/