销售司机类
package mr.map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.FloatWritable;
//import org.apache.hadoop.mapreduce.Mapper;
//import org.apache.hadoop.mapreduce.Reducer;
public class SalesDriver
{
public static void main(String args[]) throws Exception
{
Configuration c=new Configuration();
Job j=new Job(c,"Sales");
j.setJarByClass(SalesDriver.class);
j.setMapperClass(SalesMapper.class);
j.setReducerClass(SalesReducer.class);
//j.setNumReduceTasks(0);
j.setOutputKeyClass(Text.class);
j.setOutputValueClass(FloatWritable.class);
Path in=new Path(args[0]);
Path out=new Path(args[1]);
FileInputFormat.addInputPath(j, in);
FileOutputFormat.setOutputPath(j, out);
System.exit(j.waitForCompletion(true)?0:1);
}
}
销售映射器类
package mr.map;
import java.io.IOException;
//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
//import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SalesMapper extends Mapper<LongWritable, Text, Text, FloatWritable>
{
public void map(LongWritable k, Text v, Context con) throws IOException, InterruptedException
{
String w[]=v.toString().split(" ");
String product=w[3];
//String store=w[2];
//float cost=Integer.parseInt(w[4]);
float costx = Float.parseFloat(w[4]);
//String newline= product+","+store; //","+costx;
//String newline = product;
con.write(new Text(product), new FloatWritable(costx));
}
}
销售减速类
package mr.map;
import java.io.IOException;
import org.apache.hadoop.io.FloatWritable;
//import org.apache.hadoop.io.IntWritable;
//import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SalesReducer extends Reducer<Text, FloatWritable, Text, FloatWritable>
{
public void reduce(Text k, Iterable<FloatWritable>vlist, Context con) throws IOException, InterruptedException
{
int tot=0;
for (FloatWritable v:vlist)
{
tot += v.get();
}
//int total= (int)tot;
con.write(new Text(k), new FloatWritable(tot));
}
}
MapReduce 的结果
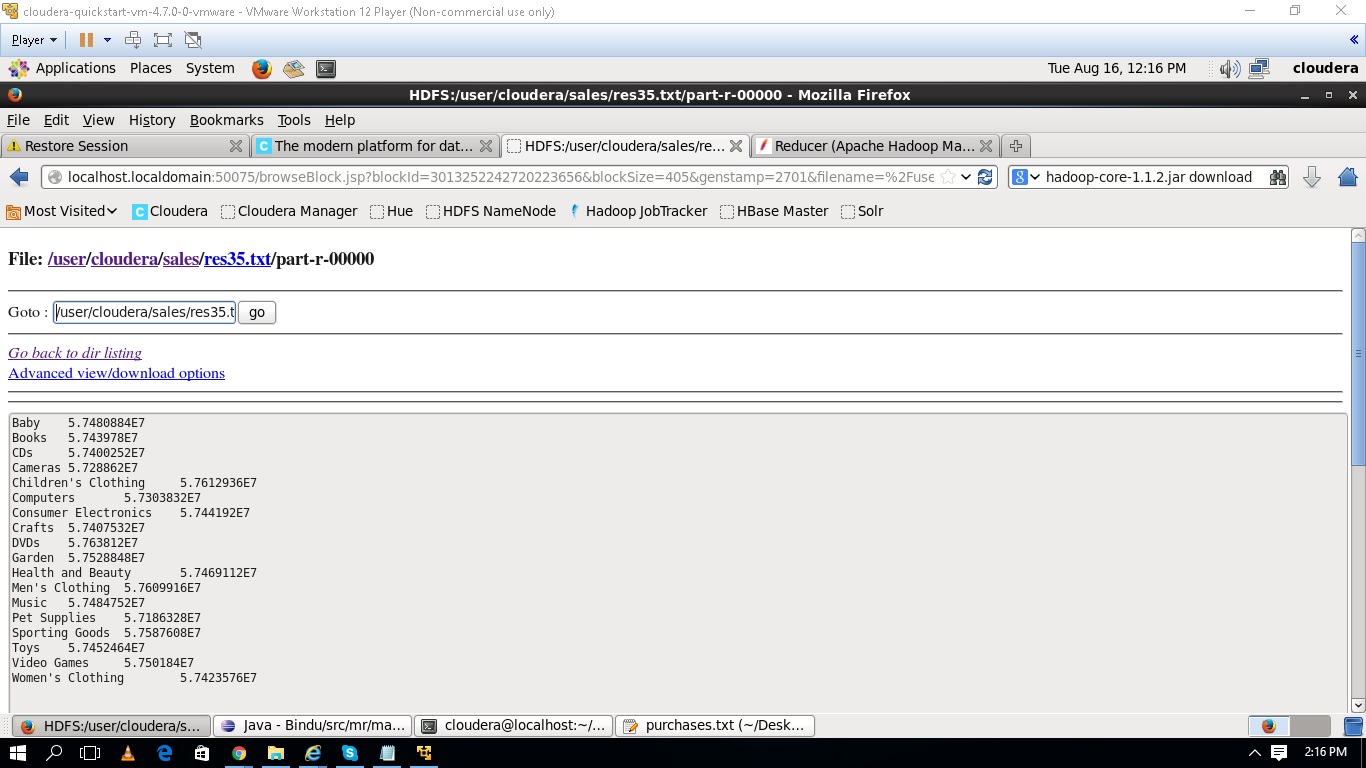
我无法理解为什么所有结果都以大 float 形式出现,并且都在数字 5.7480884E7 附近。
下面是 mapreduce 程序的输入示例:
2012-01-01 09:00 San Jose Men's Clothing 214.05 Amex
2012-01-01 09:00 Fort Worth Women's Clothing 153.57 Visa
2012-01-01 09:00 San Diego Music 66.08 Cash
2012-01-01 09:00 Pittsburgh Pet Supplies 493.51 Discover
2012-01-01 09:00 Omaha Children's Clothing 235.63 MasterCard
2012-01-01 09:00 Stockton Men's Clothing 247.18 MasterCard
2012-01-01 09:00 Austin Cameras 379.6 Visa
2012-01-01 09:00 New York Consumer Electronics 296.8 Cash
2012-01-01 09:00 Corpus Christi Toys 25.38 Discover
2012-01-01 09:00 Fort Worth Toys 213.88 Visa
2012-01-01 09:00 Las Vegas Video Games 53.26 Visa
2012-01-01 09:00 Newark Video Games 39.75 Cash
2012-01-01 09:00 Austin Cameras 469.63 MasterCard
2012-01-01 09:00 Greensboro DVDs 290.82 MasterCard
2012-01-01 09:00 San Francisco Music 260.65 Discover
2012-01-01 09:00 Lincoln Garden 136.9 Visa
2012-01-01 09:00 Buffalo Women's Clothing 483.82 Visa
2012-01-01 09:00 San Jose Women's Clothing 215.82 Cash
2012-01-01 09:00 Boston Cameras 418.94 Amex
2012-01-01 09:00 Houston Baby 309.16 Visa
2012-01-01 09:00 Las Vegas Books 93.39 Visa
2012-01-01 09:00 Virginia Beach Children's Clothing 376.11 Amex
2012-01-01 09:01 Riverside Consumer Electronics 252.88 Cash
2012-01-01 09:01 Tulsa Baby 205.06 Visa
2012-01-01 09:01 Reno Crafts 88.25 Visa
2012-01-01 09:01 Chicago Books 31.08 Cash
2012-01-01 09:01 Fort Wayne Men's Clothing 370.55 Amex
2012-01-01 09:01 San Bernardino Consumer Electronics 170.2 Cash
2012-01-01 09:01 Madison Men's Clothing 16.78 Visa
2012-01-01 09:01 Austin Sporting Goods 327.75 Discover
2012-01-01 09:01 Portland CDs 108.69 Amex
2012-01-01 09:01 Riverside Sporting Goods 15.41 Discover
2012-01-01 09:01 Reno Toys 80.46 Visa
2012-01-01 09:01 Anchorage Music 298.86 MasterCard
最佳答案
您将 float 之和的值存储在一个 int 变量中。
现在第一件事是 int 无法准确处理小数点后的浮点值。
其次,如果行数很高,则总和值可能会超出int可接受的范围。
请尝试将 tot 变量从 int 更改为 float 或 double。
double tot=0;
关于java - Reducer,Mapreduce,不显示错误,但不给出所需的输出,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/38983017/