大家好,我在从应用商店的此页面获取数据时遇到了一些问题:
app store reviews https://apps.apple.com/us/app/mathy-cool-math-learner-games/id1476596747#see-all/reviews
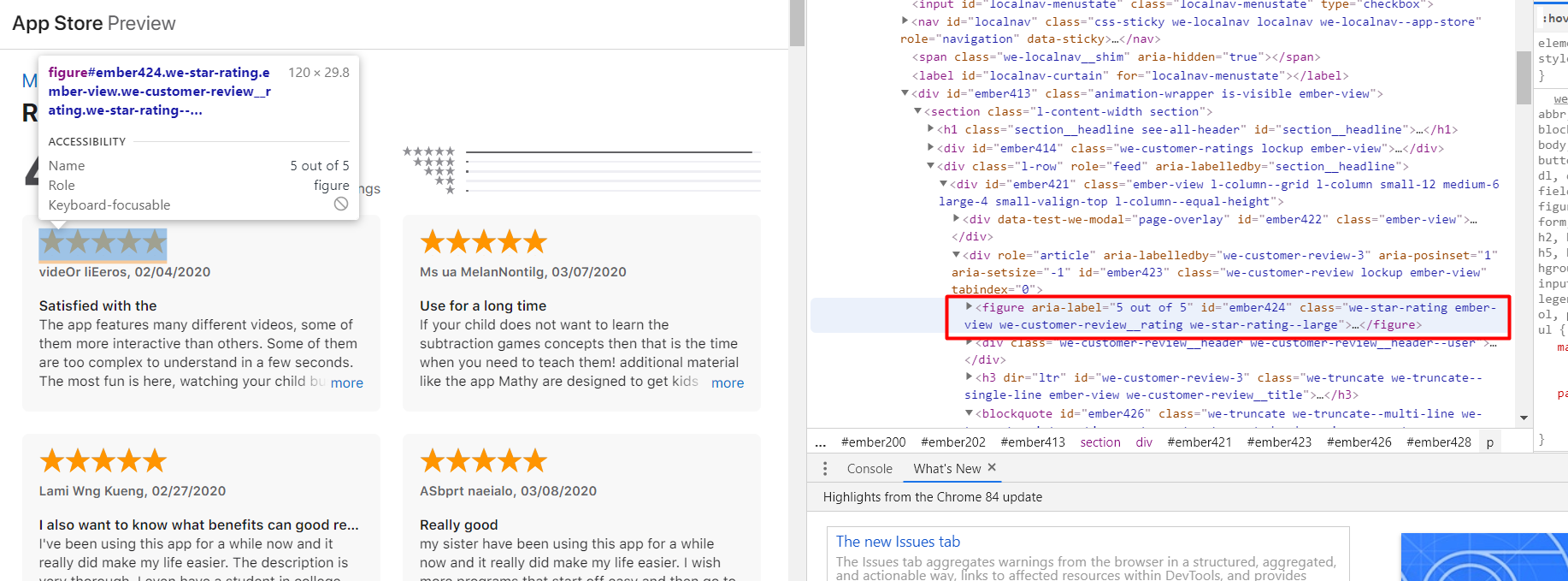
我想首先检索一个字符串,该字符串显示用户对该应用程序给出的评分。并且它们位于具有类别=“we-star-rating ember-view we-customer-review__rating we-star-rating--large”的图形标签中,并且是属性@ aria-label。
app reviews page
这是我的代码:
{kind=link}
from scrapy import Selector
import requests
html = requests.get('https://apps.apple.com/us/app/mathy-cool-math-learner-games/id1476596747#see-all/reviews').content
sel = Selector(text = html)
sel.xpath('//figure[@class="we-star-rating ember-view we-customer-review__rating we-star-rating--large"]/@aria-label').extract()
['5 out of 5', '5 out of 5', '5 out of 5']
有人可以给我一个线索吗?
最佳答案
问题
前三条评论均作为HTML的一部分加载,其余的则由javascript加载。这就是为什么您只得到前三个结果的原因。
我不确定这是否就是您使用scrapy的全部代码。我会对您为什么选择沙皮的那部分感兴趣。
因此,使用javascript处理是Web抓取现代网站的重要组成部分。我不确定您是否主要是使用scrapy进行webscrape。虽然有一些选项可用于处理JavaScript。
有关动态网页爬取的信息
首先,我们知道如今这些网站都是使用JavaScript调用HTTP请求(称为AJAX请求(异步Javascript和XHTML))动态获取信息的。这向API /服务器发出发布或获取HTTP请求,并且HTTP响应返回信息。在这种情况下,他们已将3个结果预加载到HTML中,但要求提供有关使用javascript加载页面的其余评论。
通常,有两种方法可以处理以javascript为导向的网站。
解
对于您的特定网站,您可以重新设计HTTP请求以获取所需的信息。这是理想的情况。
但是我怎么知道呢?嗯,您可以在Chrome中执行的操作之一就是关闭javascript。您必须检查页面并转到设置(单击页面最右侧的三个点->更多工具->设置)。刷新页面而不使用javascript。您会看到只有三条评论。
使用ChromeDev工具了解正在发生的事情非常有用。右键单击并检查页面时,如果转到“网络”选项卡,则将看到服务器的所有请求和响应。转到XHR选项卡,您将在其中找到包含所需数据的请求。在这里,您有一堆请求和响应。
参见下面的图片,我已经检查了页面,进入网络并刷新了页面。这将记录浏览器的请求和响应的 Activity 。

您可以看到大约有6个请求,5个GET请求和一个POST请求。如果单击每个请求,您将在右侧看到一个弹出框,其中包含请求数据,预览和响应。
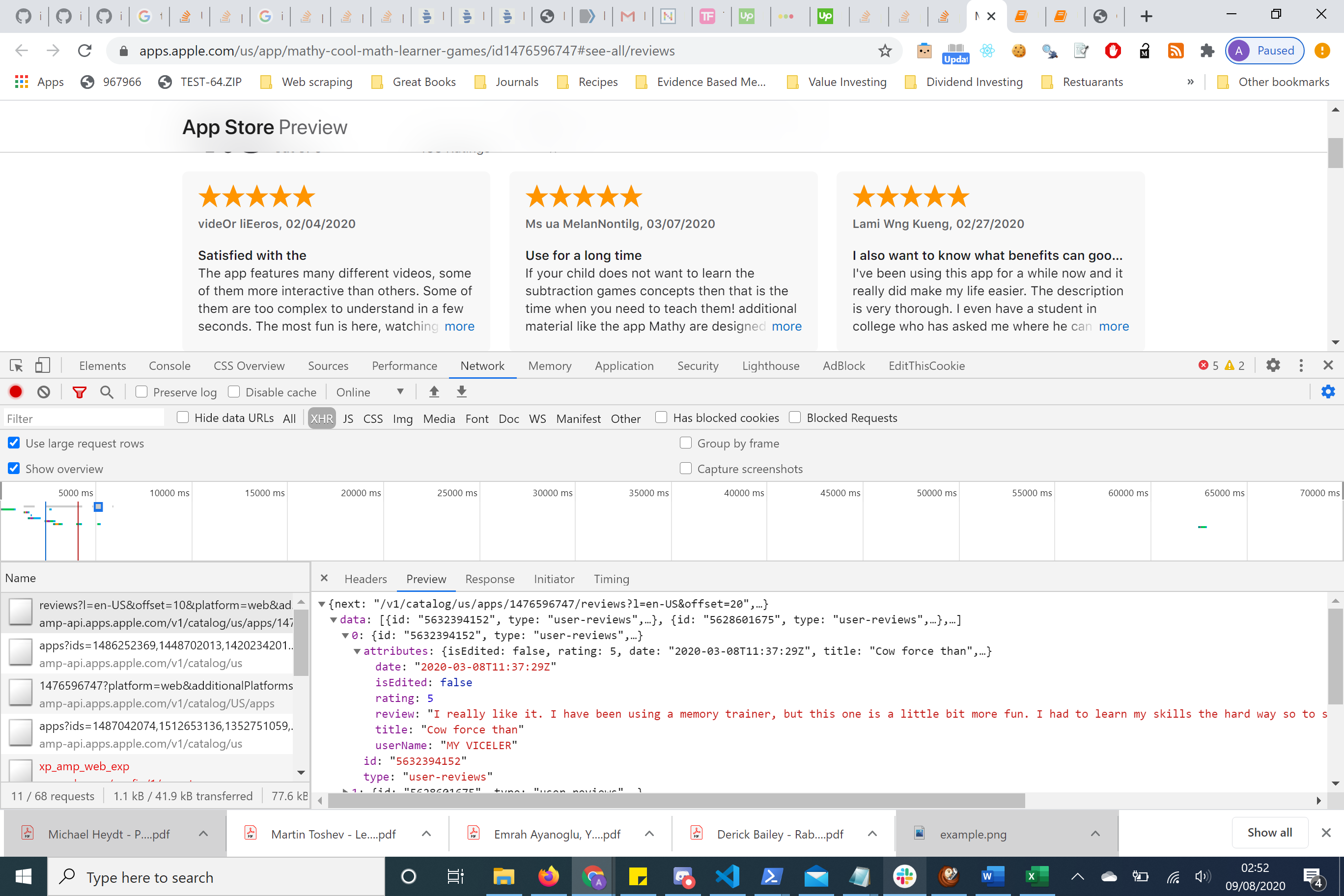
在这里,我单击了第一个请求,单击了预览,然后可以查看是否单击了某些评论。
我可以在HTTP请求中看到该数据的偏移量为10,这意味着它将捕获接下来的10个请求。
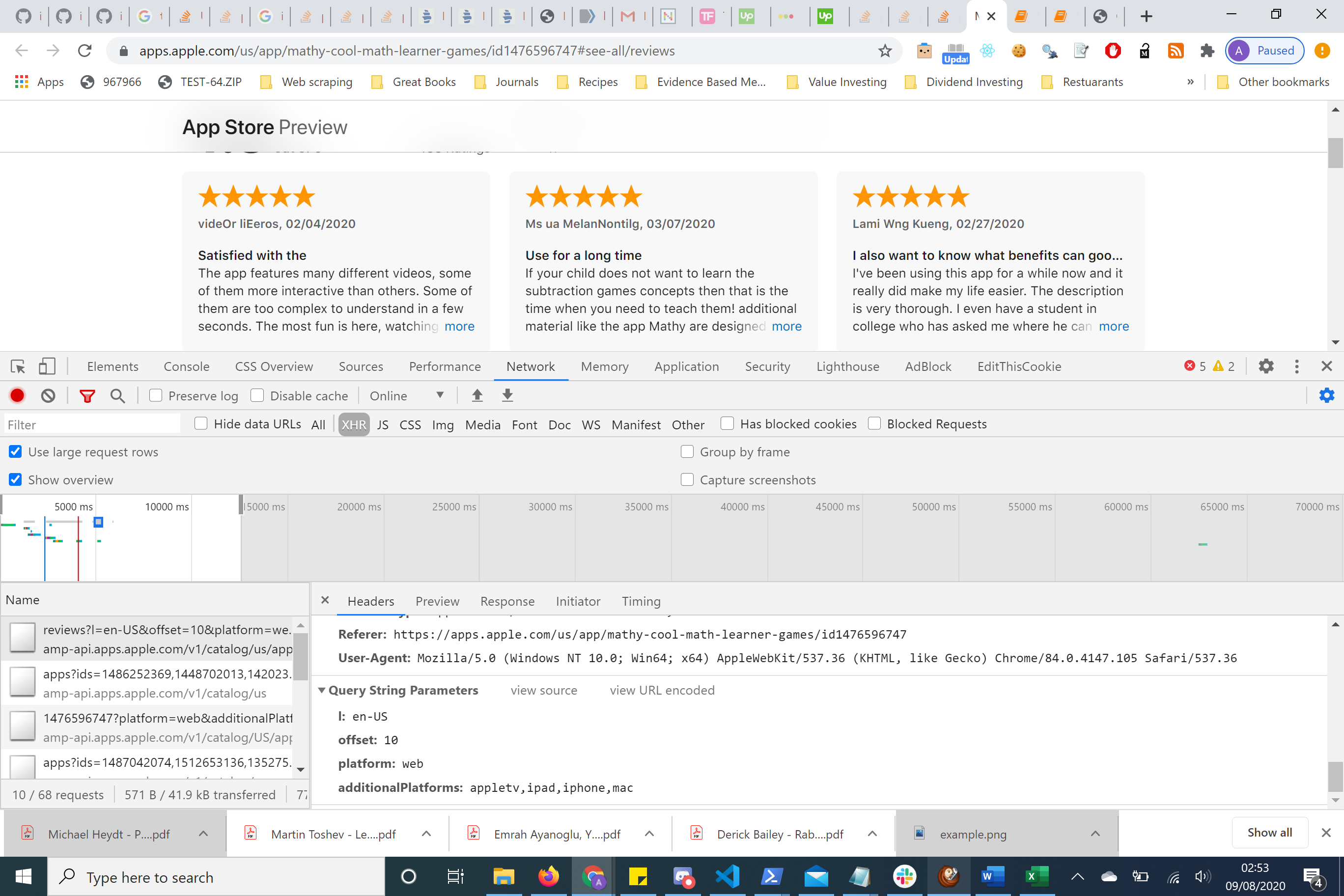
因此,我将更改该偏移量以查看是否可以获取前10个,然后获取第二个10(此页面上有20条评论)。
无需手动输入参数和标题等。您可以将请求复制到CURL。然后可以使用
curl.trillworks.com这样的网站将其转换为漂亮的python格式。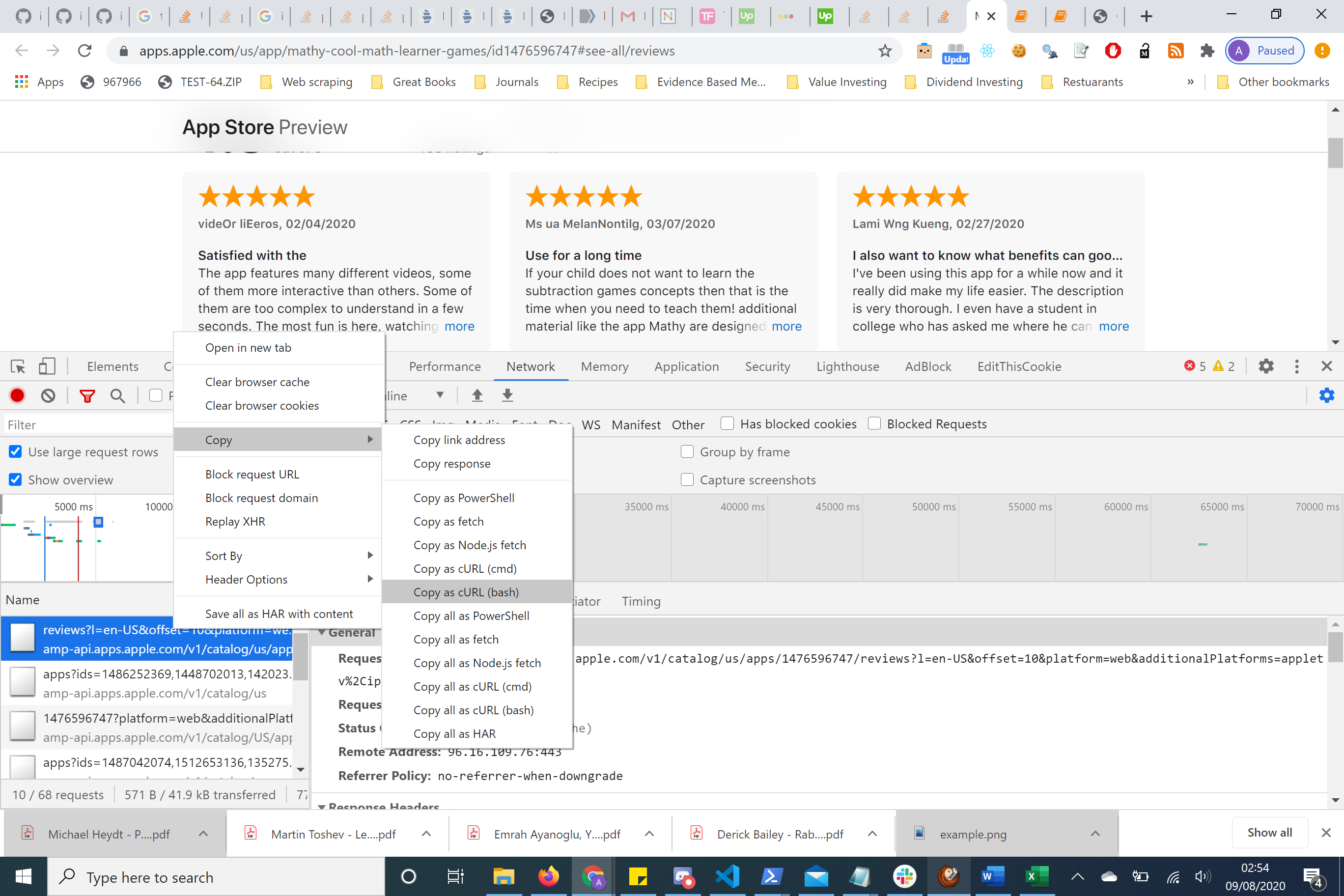
现在,值得一提的是查看预览数据,因为您将不得不使用请求来处理此数据。您将最终得到一个JSON对象,您可以从HTTP get请求的accept部分中得知它是
application/json。因此,已将此请求复制到curl.trillworks.com。我们有以下内容。
编码示例
import requests
headers = {
'Accept': 'application/json',
'Referer': 'https://apps.apple.com/us/app/mathy-cool-math-learner-games/id1476596747',
'Authorization': 'Bearer eyJhbGciOiJFUzI1NiIsInR5cCI6IkpXVCIsImtpZCI6IldlYlBsYXlLaWQifQ.eyJpc3MiOiJBTVBXZWJQbGF5IiwiaWF0IjoxNTk2NTc1NTY4LCJleHAiOjE2MTIxMjc1Njh9.jnEuBNEVWhKGqI10W6dfhJFtYJtd74Nbu1NueZrPgYjU2K34LwXPQClcus8S9Jit5ayK5MOr0bIpcDx821RI4Q',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
}
params = (
('l', 'en-US'),
('offset', '1'),
('platform', 'web'),
('additionalPlatforms', 'appletv,ipad,iphone,mac'),
)
response = requests.get('https://amp-api.apps.apple.com/v1/catalog/us/apps/1476596747/reviews', headers=headers params=params)
response.json()
request.get()而没有任何内容,然后进行构建。 json()方法将json对象格式化为python字典,因此我们可以轻松访问数据。现在,当我说查看预览时,为我们提供了访问数据所需的键和值。有时,数据可以嵌套得很深。在这种情况下不是,所以我们现在考虑循环访问此字典以获取所需的所有数据。我们必须发出两个HTTP请求,一个请求的偏移量为0,另一个请求的偏移量为10,以获得完整的20星评级。
最终代码示例
import requests
headers = {
'Accept': 'application/json',
'Referer': 'https://apps.apple.com/us/app/mathy-cool-math-learner-games/id1476596747',
'Authorization': 'Bearer eyJhbGciOiJFUzI1NiIsInR5cCI6IkpXVCIsImtpZCI6IldlYlBsYXlLaWQifQ.eyJpc3MiOiJBTVBXZWJQbGF5IiwiaWF0IjoxNTk2NTc1NTY4LCJleHAiOjE2MTIxMjc1Njh9.jnEuBNEVWhKGqI10W6dfhJFtYJtd74Nbu1NueZrPgYjU2K34LwXPQClcus8S9Jit5ayK5MOr0bIpcDx821RI4Q',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
}
for i in range(0,20,10):
params = (
('l', 'en-US'),
('offset', f'{i}'),
('platform', 'web'),
('additionalPlatforms', 'appletv,ipad,iphone,mac'),
)
response = requests.get('https://amp-api.apps.apple.com/v1/catalog/us/apps/1476596747/reviews', params=params)
data = response.json()['data']
for a in data:
print(a['attributes']['rating'])
5
5
5
5
5
...
range(0,20,10)来实现。对于每个参数,我们使用 header 和那些特定参数发出HTTP get请求。response.json()将响应转换为python字典data键内,如下所示。如果您进行打印,则会得到以下输出。数据= response.json()['数据']
打印(数据)
输出量
{'id': '5632394152',
'type': 'user-reviews',
'attributes': {'review': "I really like it. I have been using a memory trainer, but this one is a little bit more fun. I had to learn my skills the hard way so to speak, but it is really fun! I can't wait to buy it again! 😁🤓",
'rating': 5,
'title': 'Cow force than',
'date': '2020-03-08T11:37:29Z',
'userName': 'MY VICELER',
'isEdited': False}}
attributes键之后,然后在rating键后面。因此,我们要遍历response.json()['data'])并访问a ['attribute'] ['value'],这将为我们提供输出。 关于python - Scrapy:无法检索App Store的评论页面,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/63321409/