使用 Fetch API,我可以对大量二进制数据(比如超过 500 MB)发出网络请求,然后转换 Response到 Blob或 ArrayBuffer .
之后,我可以做 worker.postMessage并让标准结构化克隆算法复制 Blob转移到 Web Worker 或转移 ArrayBuffer转移到工作人员上下文(有效地不再可从主线程获得)。
起初,似乎最好将数据作为 ArrayBuffer 获取。 , 因为 Blob不可转让,因此需要复制。但是,blob 是不可变的,因此,浏览器似乎不会将其存储在与页面关联的 JS 堆中,而是存储在专用的 blob 存储空间中,因此,最终被复制到工作上下文的只是一个引用。
我准备了一个演示来尝试两种方法之间的区别:https://blobvsab.vercel.app/ .我正在使用这两种方法获取 656 MB 的二进制数据。
我在本地测试中观察到的一些有趣的事情是,复制 Blob 甚至比传输 ArrayBuffer 还要快。 :Blob从主线程复制到工作线程的时间:1.828125 msArrayBuffer从主线程到工作线程的传输时间:3.393310546875 ms
这是一个强有力的指标,表明处理 Blob 实际上非常便宜。由于它们是不可变的,浏览器似乎足够聪明,可以将它们视为引用,而不是将覆盖的二进制数据链接到这些引用。
这是我在获取 Blob 时拍摄的堆内存快照:

前两个快照是在生成 Blob 之后拍摄的。使用 postMessage 将获取的次数复制到工作程序上下文中.请注意,这些堆都不包括 656 MB。
后两张快照是在我使用 FileReader 之后拍摄的。实际访问底层数据,正如预期的那样,堆增长了很多。
现在,这就是直接作为 ArrayBuffer 获取所发生的情况。 :
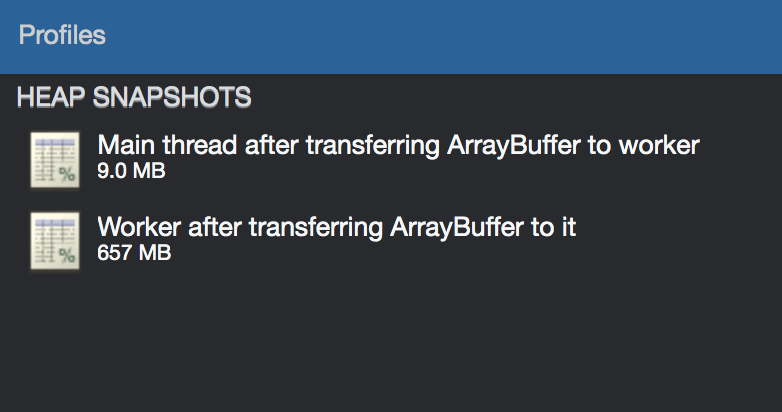
在这里,由于二进制数据只是通过工作线程传输的,因此主线程的堆很小,但工作堆包含全部 656 MB,甚至在读取此数据之前。
现在,环顾四周,我看到 What is the difference between an ArrayBuffer and a Blob?提到了两种结构之间的许多潜在差异,但我还没有找到一个很好的引用资料来说明是否应该担心复制 Blob。在执行上下文与 ArrayBuffer 的固有优势之间它们是可转让的。但是,我的实验表明,复制 Blob实际上可能更快,因此我认为更可取。
似乎取决于每个浏览器 vendor 他们如何存储和处理 Blob s。我找到了 this Chromium documentation描述所有Blobs从每个渲染器进程(即选项卡上的页面)传输到浏览器进程,这样 Chrome 甚至可以卸载 Blob如果需要,可以到辅助存储器。
有没有人对这一切有更多的见解?如果我可以选择通过网络获取一些大型二进制数据并将其移动到 Web Worker,我应该更喜欢 Blob或 ArrayBuffer ?
最佳答案
不,postMessage 一个 Blob 一点也不贵。
cloning steps一个 Blob 是
Their serialization steps, given value and serialized, are:
Set serialized.[[SnapshotState]] to value’s snapshot state.
Set serialized.[[ByteSequence]] to value’s underlying byte sequence.
Their deserialization step, given serialized and value, are:
Set value’s snapshot state to serialized.[[SnapshotState]].
Set value’s underlying byte sequence to serialized.[[ByteSequence]].
换句话说,没有任何内容被复制,快照状态和字节序列都是通过引用传递的(即使包装 JS 对象不是)。
但是,对于您的整个项目,我不建议在这里使用 Blob,原因有两个:
关于javascript - 将大 blob 复制给 worker 是否昂贵?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/63641798/