以下代码来自“破解编码面试”一书。该代码打印字符串的所有排列。
问题 : 下面代码的时间复杂度是多少。
void permutation(String str) {
permutation(str, "");
}
private void permutation(String str, String prefix) {
if (str.length() == 0){
System.out.println(prefix);
} else {
for (int i = 0; i <str.length(); i++) {
String rem = str.substring(0, i) + str.substring(i + 1);
permutation(rem, prefix + str.charAt(i));
}
}
}
我的理解:
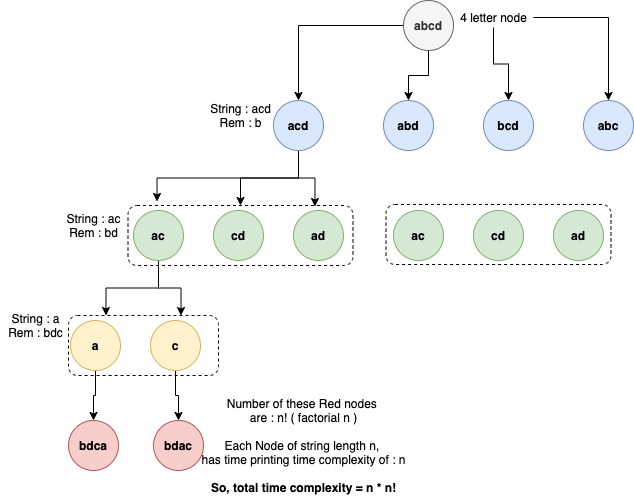
我能够将时间复杂度推导出为:n * n!。
我确定我错过了蓝色、绿色和黄色节点的时间复杂度。但尽管反复尝试,始终没有明确能够找出出路。
有人可以分享一些输入,最好是例子吗?
最佳答案
您在这里非常正确,您的总体评估(运行时间为 Θ(n · n!))是正确的!我们可以用来推导运行时的一种技术是总结树中每一层所做的工作。我们知道
考虑到这里完成的全部工作,我们假设每个递归调用在基线上执行 O(1) 工作,加上与它正在处理的字符串长度成正比的工作。这意味着我们需要计算两个总和来确定完成的总工作量:
Sum 1: Number of Calls
1 + n + n(n-1) + n(n-1)(n-2) + ... + n!
和
Sum 2: Work Processing Strings
1 · n + n · (n-1) + n(n-1)·(n-2) + ... + n! · 0
但是还有一个其他因素需要考虑 - 每个遇到基本情况的递归调用都会打印出以这种方式生成的字符串,这需要 O(n) 时间。所以这增加了 Θ(n·n!) 的最终因子。因此,完成的总工作量将是 Θ(n·n!),加上所有构建答案的中间递归调用所做的工作量。
让我们分别对待这些总和。
总和 1:调用次数
我们正在处理这个不寻常的总和:
1 + n + n(n-1) + n(n-1)(n-2) + ... + n!
我们需要的主要观察是
所以,换句话说,这个总和是
n! / n! + n! / (n-1)! + n! / (n-2)! + ... + n! / 0!
= n!(1 / n! + 1/(n-1)! + 1/(n-2)! + ... + 1/0!)
≤ en!
= Θ(n!)
在这里,最后一步来自于总和
1/0! + 1/1! + 1/2! + 1/3! + ...
out to infinity 是定义数 e 的方法之一。这意味着这里进行的递归调用总数为 Θ(n!)。
而且,直觉上,这应该是有道理的。每次递归调用,除了对长度为 1 的字符串的递归调用外,还会进行另外两次递归调用,因此递归树大多是分支的。关于树有一个很好的事实,即每个节点都有分支的树的内部节点不会多于叶子。既然有 n!叶,剩余的节点数出现不渐近大于 n! 的东西也就不足为奇了。
总和 2:工作处理字符串
这是总和
1 · n + n · (n-1) + n(n-1)·(n-2) + ... + n! · 0
我们可以将其重写为
n + n(n-1) + n(n-1)(n-2) + ...
嘿!我们知道那个总和 - 它几乎与我们刚刚看到的相同。这适用于 Θ(n!)。
把它放在一起
总而言之,这个递归算法确实
总结这一切给出了 Θ(n·n!) 您在问题中提出的运行时。
希望这可以帮助!
关于java - 时间复杂度 : Getting incorrect result,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/61539024/