我有一个作业处理器需要并行处理大约 300 个作业(作业最多可能需要 5 分钟才能完成,但它们通常受网络限制)。
我遇到的问题是,工作往往是特定类型的。为简单起见,假设有六种作业类型,JobA 到 JobF。
JobA - JobE 是网络绑定(bind)的,可以非常愉快地同时运行 300 个而不会对系统造成负担(实际上,我已经设法运行了 1,500 多个在测试中并排)。 JobF(一种新的作业类型)也是网络绑定(bind)的,但它需要大量内存并且实际上使用了 GDI 功能。
我确保使用 using 小心处理所有 GDI 对象,并且根据探查器,我没有泄漏任何东西。只是并行运行 300 个 JobF 使用的内存比 .NET 愿意给我的要多。
处理此问题的最佳做法是什么?我的第一个想法是确定我有多少内存开销,并在接近极限时限制生成新作业(至少 JobF 作业)。我无法实现这一点,因为我找不到任何方法来可靠地确定框架愿意根据内存分配给我什么。我还必须猜测作业使用的最大内存,这看起来有点古怪。
我的下一个计划是,如果出现 OOM 并重新安排失败的作业,则简单地进行限制。不幸的是,OOM 可以发生在任何地方,而不仅仅是在有问题的作业中。事实上,最常见的地方是管理作业的主工作线程。按照目前的情况,这会导致进程正常关闭(如果可能)、重新启动并尝试恢复。虽然这行得通,但它很糟糕并且浪费时间和资源 - 比仅仅回收该特定工作要糟糕得多。
是否有处理这种情况的标准方法(添加更多内存是一种选择并且会完成,但应用程序应该正确处理这种情况,而不仅仅是炸毁)?
最佳答案
我正在做一些与你的情况非常相似的事情,我选择了一种方法,在这种方法中,我有一个任务处理器(在一个节点上运行的主队列管理器)和在一个或多个节点上运行的尽可能多的代理。
每个代理都作为一个单独的进程运行。他们:
- 检查任务可用性
- 下载所需数据
- 处理数据
- 上传结果
队列管理器的设计方式是,如果任何代理在作业执行期间失败,它会在一段时间后简单地重新分配给另一个代理。
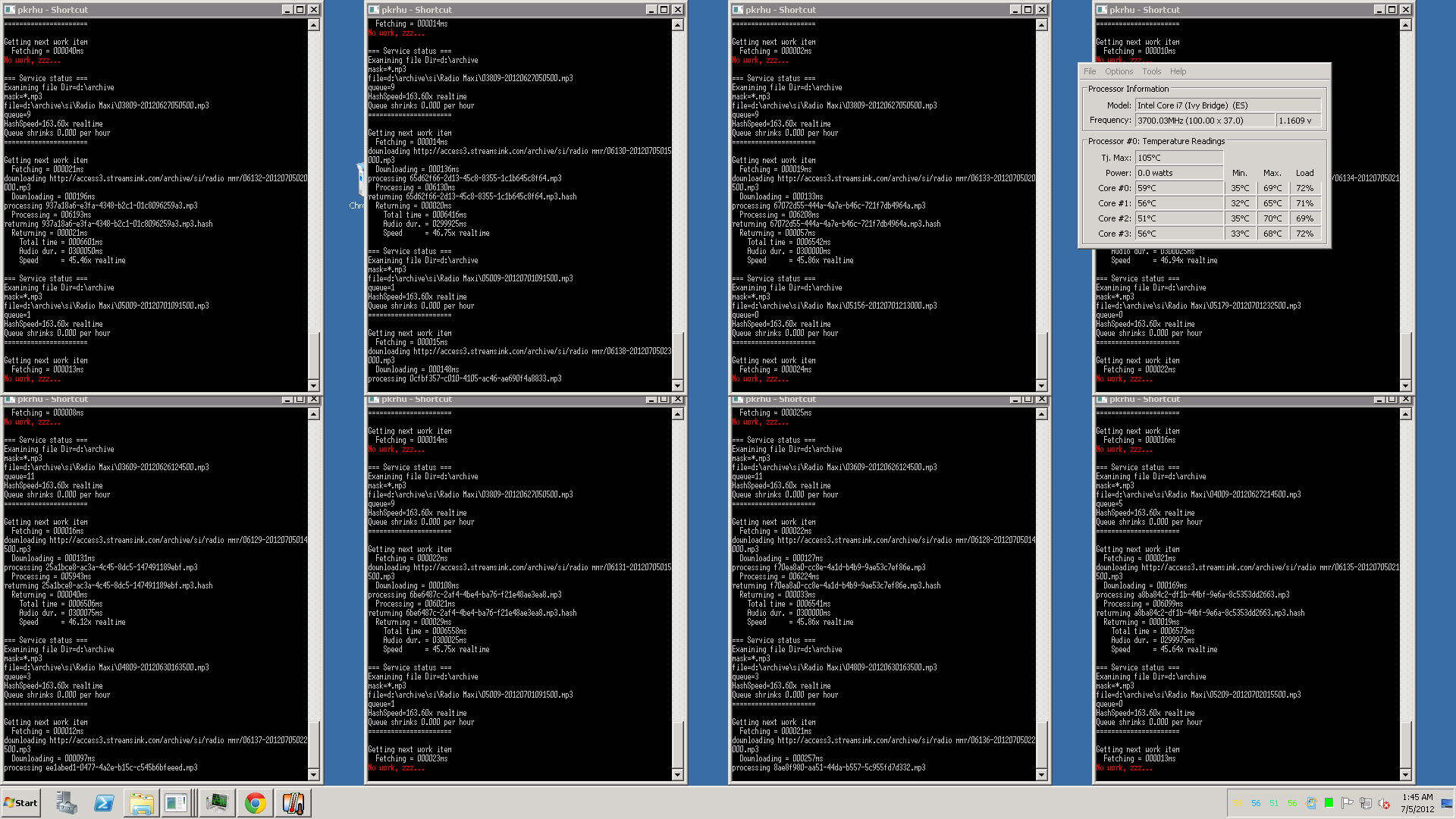
顺便说一句,考虑不要同时并行运行所有任务,因为在切换上下文时确实存在一些开销(可能很大)。在您的情况下,您可能会使网络充满不必要的 PROTOCOL 流量而不是真实的 DATA 流量。
此设计的另一个优点是,如果我开始在数据处理方面落后,我总是可以再打开一台机器(比如 Amazon C2 实例)并运行更多代理,这将有助于更快地完成任务库.
回答你的问题:
每台主机都会尽可能多地使用,因为在一台主机上运行的代理数量有限。完成一项任务后,将执行另一项任务并无限期地进行。我不使用数据库。任务不是时间紧迫的,所以我有一个进程在传入的数据集上来回走动,并在之前运行失败时创建新任务。具体来说:
http://access3.streamsink.com/archive/ (源数据)
http://access3.streamsink.com/tbstrips/ (计算结果)
在每次队列管理器运行时,扫描源和目标,减去结果集并将文件名转换为任务。
还有一些:
我正在使用网络服务来获取工作信息/返回结果,并使用简单的 http 来获取要处理的数据。
最后:
这是我拥有的 2 个经理/代理对中比较简单的一个 - 另一个在某种程度上更复杂,所以我不会在这里详细介绍。使用电子邮件:)
关于.net - 在 .NET 中优雅地处理内存不足异常(或完全避免它),我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/11332800/