我将 X 和 y 中的特征分开,然后在使用 k 折交叉验证拆分后预处理我的火车测试数据。之后,我将训练数据拟合到我的随机森林回归模型并计算置信度分数。为什么要在拆分后进行预处理?因为人们告诉我这样做更正确,而且为了我的模型性能,我一直坚持这一原则。
这是我第一次使用 KFold 交叉验证,因为我的模型得分过高,我认为我可以通过交叉验证来修复它。我仍然对如何使用它感到困惑,我已经阅读了文档和一些文章,但我并没有真正理解如何将它真正暗示到我的模型中,但我还是尝试了,但我的模型仍然过拟合。使用火车测试拆分或交叉验证导致我的模型分数仍然是 0.999,我不知道我的错误是什么,因为我是使用这种方法的新手,但我想也许我做错了,所以它没有修复过度拟合。请告诉我我的代码有什么问题以及如何解决这个问题
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestRegressor
import scipy.stats as ss
avo_sales = pd.read_csv('avocados.csv')
avo_sales.rename(columns = {'4046':'small PLU sold',
'4225':'large PLU sold',
'4770':'xlarge PLU sold'},
inplace= True)
avo_sales.columns = avo_sales.columns.str.replace(' ','')
x = np.array(avo_sales.drop(['TotalBags','Unnamed:0','year','region','Date'],1))
y = np.array(avo_sales.TotalBags)
# X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
kf = KFold(n_splits=10)
for train_index, test_index in kf.split(x):
X_train, X_test, y_train, y_test = x[train_index], x[test_index], y[train_index], y[test_index]
impC = SimpleImputer(strategy='most_frequent')
X_train[:,8] = impC.fit_transform(X_train[:,8].reshape(-1,1)).ravel()
X_test[:,8] = impC.transform(X_test[:,8].reshape(-1,1)).ravel()
imp = SimpleImputer(strategy='median')
X_train[:,1:8] = imp.fit_transform(X_train[:,1:8])
X_test[:,1:8] = imp.transform(X_test[:,1:8])
le = LabelEncoder()
X_train[:,8] = le.fit_transform(X_train[:,8])
X_test[:,8] = le.transform(X_test[:,8])
rfr = RandomForestRegressor()
rfr.fit(X_train, y_train)
confidence = rfr.score(X_test, y_test)
print(confidence)
最佳答案
过度拟合的原因是基于非正则化树的模型会调整数据,直到所有训练样本都被正确分类。参见例如这张图片:
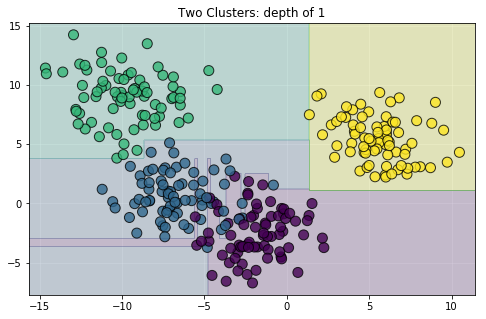
如您所见,这并不能很好地概括。如果您不指定对树进行正则化的参数,则该模型将无法很好地拟合测试数据,因为它基本上只会学习训练数据中的噪音。 sklearn中有很多正则化树的方法,你可以找到它们here .例如:
- 最大特征数
- min_samples_leaf
- 最大深度
通过适当的正则化,您可以获得一个可以很好地泛化到测试数据的模型。以正则化模型为例:
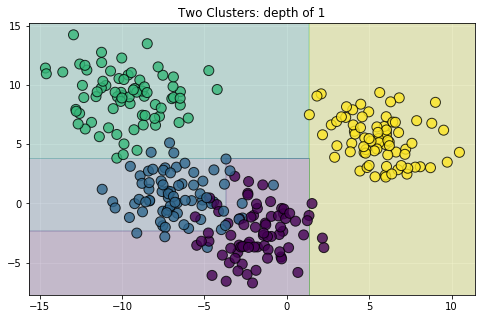
要规范化您的模型,请像这样实例化 RandomForestRegressor() 模块:
rfr = RandomForestRegressor(max_features=0.5, min_samples_leaf=4, max_depth=6)
这些参数值是任意的,您可以找到最适合您的数据的值。您可以使用特定领域的知识来选择这些值,或者使用超参数调整搜索,如 GridSearchCV 或 RandomizedSearchCV。
除此之外,估算均值和中位数可能会给您的数据带来很多噪音。除非你别无选择,否则我会反对它。
关于python - KFold 交叉验证无法修复过度拟合,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/60684943/