我正在对这个网站进行网络抓取:
http://www.falabella.com.pe/falabella-pe/category/cat40536/Climatizacion?navAction=push
我只需要产品信息:“品牌”、“产品名称”、“价格”。

我可以得到,但我也可以从其他用户的类似产品的横幅中获取信息。我不需要它。
但是当我转到页面的源代码时,我看不到那些产品。我认为它是通过javascript或其他东西拉出来的:
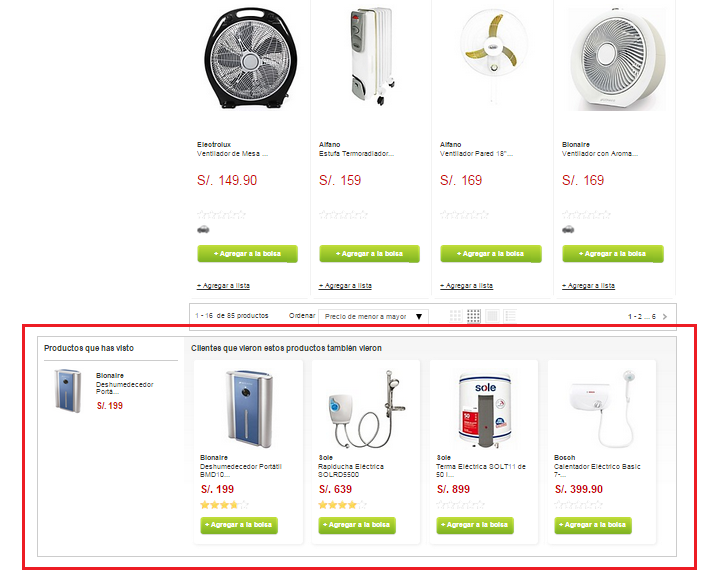
问题 1: 在进行网络抓取时如何阻止这些信息? 这会添加我不需要的产品。但是在源码中看不到这部分。
问题 2:提取价格“precio1”时,我将其作为第一个元素:"\n\t\t\t\tSubtotal InternetS/.0" 我在代码源中也看不到。怎么不刮呢?
library(RSelenium)
library(rvest)
#start RSelenium
checkForServer()
startServer()
remDr <- remoteDriver()
remDr$open()
#navigate to your page
remDr$navigate("http://www.falabella.com.pe/falabella-pe/category/cat40536/Climatizacion?navAction=push")
page_source<-remDr$getPageSource()
Climatizacion_marcas1 <- html(page_source[[1]])%>%
html_nodes(".marca") %>%
html_nodes("a") %>%
html_attr("title")
Climatizacion_producto1 <- html(page_source[[1]])%>%
html_nodes(".detalle") %>%
html_nodes("a") %>%
html_attr("title")
Climatizacion_precio1 <- html(page_source[[1]])%>%
html_nodes(".precio1") %>%
html_text()
最佳答案
保持接近你的方法,这会做到:
library(rvest)
u <- "http://www.falabella.com.pe/falabella-pe/category/cat40536/Climatizacion?navAction=push"
doc <- html(u)
Climatizacion_marcas1 <- doc %>%
html_nodes(".marca")[[1]] %>%
html_nodes("a") %>%
html_attr("title")
Climatizacion_producto1 <- doc %>%
html_nodes(".detalle") %>%
html_nodes("a") %>%
html_attr("title")
“\n\t\t”等来自于对html的解析。显然,那里有回车和制表符。一个简单的解决方案是:
Climatizacion_precio1 <- doc %>%
html_node(".precio1") %>%
html_text() %>%
stringr::str_extract_all("[:number:]{1,4}[.][:number:]{1,2}", simplify = TRUE) %>%
as.numeric
Climatizacion_precio1
[1] 44.9
实际上,这会从字符串中选择数字(因此也会删除“S/.”。如果您希望“S/.”保留,您可以执行以下操作:
Climatizacion_precio1 <- doc %>%
html_node(".precio1") %>%
html_text() %>%
gsub('[\r\n\t]', '', .)
Climatizacion_precio1
[1] "S/. 44.90"
编辑
这是另一种方法,使用 XML 和 selectr。这将一次性获取页面上所有项目的信息。
library(XML)
clean_up <- function(x) {
stringr::str_replace_all(x, "[\r\t\n]", "")
}
product <- selectr::querySelectorAll(doc, ".marca") %>%
xmlApply(xmlValue) %>% lapply(clean_up) %>% unlist
details <- selectr::querySelectorAll(doc, ".detalle a") %>%
xmlApply(xmlValue) %>%
unlist
price <- selectr::querySelectorAll(doc, ".precio1") %>%
xmlApply(xmlValue) %>% lapply(clean_up) %>% unlist
as.data.frame(cbind(product, details, price))
product details price
1 Imaco Termoventilador NF15... S/. 44.90
2 Imaco Ventilador de 10" I... S/. 69
3 Imaco Ventilador Imaco de ... S/. 89
4 Taurus Recirculador TRA-30 ... S/. 89
5 Imaco Termoventilador ITC-... S/. 109
6 Sole Termo Ventilador Elé... S/. 99
7 Taurus Ventilador TVP-40 3 ... S/. 99
8 Imaco Estufa OFR7AO 1.500 ... S/. 129
9 Alfano Ventilador Recircula... S/. 139
10 Taurus Ventilador TVC-40RC ... S/. 139
11 Imaco Ventilador Pedestal ... S/. 149
12 Alfano Ventilador Orbital 1... S/. 149
13 Electrolux Ventilador de Mesa ... S/. 149.90
14 Alfano Estufa Termoradiador... S/. 159
15 Alfano Ventilador Pared 18"... S/. 169
16 Imaco Termoradiador OFR9AO S/. 179
您通常可能希望对结果进行一些初步清理。
关于R:Rvest - 得到了我不想要的隐藏文本,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/30541445/