这是示例数据:
myd <- data.frame (matrix (sample (c("AB", "BB", "AA"), 100*100,
replace = T), ncol = 100))
variablenames= paste (rep (paste ("MR.", 1:10,sep = ""),
each = 10), 1:100, sep = ".")
names(myd) <- variablenames
每个变量都有一个组,这里我们有十组。因此,此数据框中每个变量的组索引如下:
group <- rep(1:10, each = 10)
因此变量名和组
data.frame (group, variablenames)
group variablenames
1 1 MR.1.1
2 1 MR.1.2
3 1 MR.1.3
4 1 MR.1.4
5 1 MR.1.5
6 1 MR.1.6
7 1 MR.1.7
8 1 MR.1.8
9 1 MR.1.9
10 1 MR.1.10
11 2 MR.2.11
<<<<<<<<<<<<<<<<<<<<<<<<
100 10 MR.10.100
每个组意味着以下步骤将分别应用于一组变量。
我有更长的功能可以工作,下面是一个简短的例子:
同时考虑两个变量的函数
myfun <- function (x1, x2) {
out <- NULL
out <- paste(x1, x2, sep=":")
# for other steps to be performed here
return (out)
}
# group 1
myfun (myd[,1], myd[,2]); myfun (myd[,3], myd[,4]); myfun (myd[,5], myd[,6]);
myfun (myd[,7], myd[,8]); myfun (myd[,9], myd[,10]);
# group 2
myfun (myd[,11], myd[,12]); myfun (myd[,13], myd[,14]); .......so on to group 10 ;
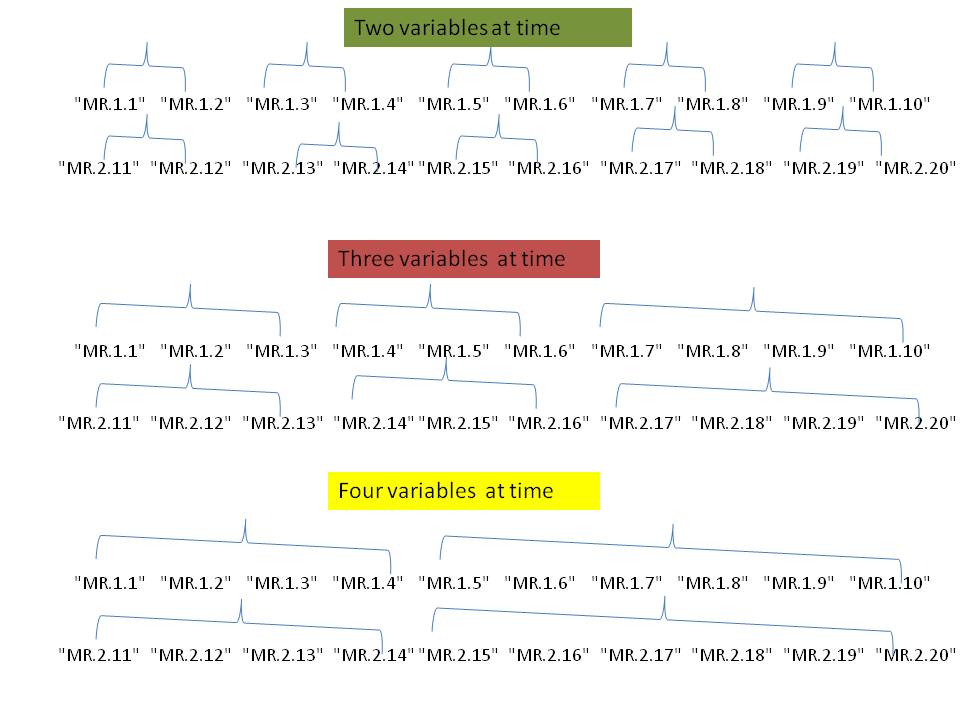
这样我需要走变量 1:10(即在第一组中执行上述操作),然后是 11:20(第二组)。在这种情况下,组无关紧要,每个组中的变量数量可以被一次(2)采用(考虑)的变量数量(10)整除。
但是在以下示例中,一次取 3 个变量 - 每组中的总变量数 (3),10/3,最后还剩下一个变量。
同时考虑三个变量的函数。
myfun <- function (x1, x2, x3) {
out <- NULL
out <- paste(x1, x2, x3, sep=":")
# for other steps to be performed here
return (out)
}
# for group 1
myfun (myd[,1], myd[,2], myd[,3])
myfun (myd[,4], myd[,5], myd[,6])
myfun (myd[,7], myd[,8], myd[,9])
# As there one variable left before proceedomg to second group, the final group will
have 1 extra variable
myfun (myd[,7], myd[,8], myd[,9],myd[,10] )
# for group 2
myfun (myd[,11], myd[,12], myd[,13])
# and to the end all groups and to end of the file.
我想通过用户定义的 n 个变量来循环这个过程,其中 n 可以是 1 到每组中的最大变量数。
编辑:只是展示过程的插图(例如仅演示了第 1 组和第 2 组):
最佳答案
创建一个函数,将您的数据拆分为适当的列表,并将您想要的任何函数应用到您的列表。
此函数将创建您的第二个 分组变量。 (第一个分组变量 (group) 在您的问题中提供;如果您更改该值,您还应该在下面的函数中更改 DIM。)
myfun = function(LENGTH, DIM = 10) {
PATTERN = rep(1:(DIM %/% LENGTH), each=LENGTH)
c(PATTERN, rep(max(PATTERN), DIM %% LENGTH))
}
这里是我们将拆分 myd 的组。在这个例子中,我们首先将 myd 分成 10 列组,每组分为 3 列组,除了最后一组,它将有 4 列(3+3+4 = 10 ).
NOTE: To change the number of columns you're grouping by, for example, grouping by two variables at a time, change
group2 = rep(myfun(3), length.out=100)togroup2 = rep(myfun(2), length.out=100).
group <- rep(1:10, each = 10)
# CHANGE THE FOLLOWING LINE ACCORDING
# TO THE NUMBER OF GROUPS THAT YOU WANT
group2 = rep(myfun(3), length.out=100)
这就是拆分过程。我们首先仅按名称拆分,并将这些名称与 myd 匹配以创建 data.frames 列表。
# Extract group names for matching purposes
temp = split(names(myd), list(group, group2))
# Match the names to myd
temp = lapply(1:length(temp),
function(x) myd[, which(names(myd) %in% temp[[x]])])
# Extract the names from the list for future reference
NAMES = lapply(temp, function(x) paste(names(x), collapse="_"))
现在我们有了一个列表,我们可以做很多有趣的事情。你想将你的列粘贴在一起,用冒号分隔。以下是您的操作方式。
# Do what you want with the list
# For example, to paste the columns together:
FINAL = lapply(temp, function(x) apply(x, 1, paste, collapse=":"))
names(FINAL) = NAMES
这是输出示例:
lapply(FINAL, function(x) head(x, 5))
# $MR.1.1_MR.1.2_MR.1.3
# [1] "AA:AB:AB" "AB:BB:AA" "BB:AB:AA" "BB:AA:AB" "AA:AA:AA"
#
# $MR.2.11_MR.2.12_MR.2.13
# [1] "BB:AA:AB" "BB:AB:BB" "BB:AA:AA" "AB:BB:AA" "BB:BB:AA"
#
# $MR.3.21_MR.3.22_MR.3.23
# [1] "AA:AB:BB" "BB:AA:AA" "AA:AB:BB" "AB:AA:AA" "AB:BB:BB"
#
# <<<<<<<------SNIP------>>>>>>>>
#
# $MR.1.4_MR.1.5_MR.1.6
# [1] "AB:BB:AA" "BB:BB:BB" "AA:AA:AA" "BB:BB:AB" "AB:AA:AA"
#
# $MR.2.14_MR.2.15_MR.2.16
# [1] "AA:BB:AB" "BB:BB:BB" "BB:BB:AB" "AA:BB:AB" "BB:BB:BB"
#
# $MR.3.24_MR.3.25_MR.3.26
# [1] "AA:AB:BB" "BB:AA:BB" "BB:AB:BB" "AA:AB:AA" "AB:AA:AA"
#
# <<<<<<<------SNIP------>>>>>>>>
#
# $MR.1.7_MR.1.8_MR.1.9_MR.1.10
# [1] "AB:AB:AA:AB" "AB:AA:BB:AA" "BB:BB:AA:AA" "AB:BB:AB:AA" "AB:BB:AB:BB"
#
# $MR.2.17_MR.2.18_MR.2.19_MR.2.20
# [1] "AB:AB:BB:BB" "AB:AB:BB:BB" "AB:AA:BB:BB" "AA:AA:AB:AA" "AB:AB:AB:AB"
#
# $MR.3.27_MR.3.28_MR.3.29_MR.3.30
# [1] "BB:BB:AB:BB" "BB:BB:AA:AA" "AA:BB:AB:AA" "AA:BB:AB:AA" "AA:AB:AA:BB"
#
# $MR.4.37_MR.4.38_MR.4.39_MR.4.40
# [1] "BB:BB:AB:AA" "AA:BB:AA:BB" "AA:AA:AA:AB" "AB:AA:BB:AB" "BB:BB:BB:BB"
#
# $MR.5.47_MR.5.48_MR.5.49_MR.5.50
# [1] "AB:AA:AA:AB" "AB:AA:BB:AA" "AB:BB:AA:AA" "AB:BB:BB:BB" "BB:AA:AB:AA"
#
# $MR.6.57_MR.6.58_MR.6.59_MR.6.60
# [1] "BB:BB:AB:AA" "BB:AB:BB:AA" "AA:AB:AB:BB" "BB:AB:AA:AB" "AB:AA:AB:BB"
#
# $MR.7.67_MR.7.68_MR.7.69_MR.7.70
# [1] "BB:AB:BB:AA" "BB:AB:BB:AA" "BB:AB:BB:AB" "AB:AA:AA:AA" "AA:AA:AA:AB"
#
# $MR.8.77_MR.8.78_MR.8.79_MR.8.80
# [1] "AA:AB:AA:AB" "AB:AA:AB:BB" "BB:BB:AA:AB" "AB:BB:BB:BB" "AB:AA:BB:AB"
#
# $MR.9.87_MR.9.88_MR.9.89_MR.9.90
# [1] "AA:BB:AB:AA" "AA:AB:BB:BB" "AA:BB:AA:BB" "AB:AB:AA:BB" "AB:AA:AB:BB"
#
# $MR.10.97_MR.10.98_MR.10.99_MR.10.100
# [1] "AB:AA:BB:AB" "AB:AA:AB:BB" "BB:AB:AA:AA" "BB:BB:AA:AA" "AB:AB:BB:AB"
关于r - 选择 n 个后续分组变量并在 r 中应用该函数,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/11780194/