我对包含数百万行的表进行了数据透视查询。正常运行查询,运行2秒,返回2983行。如果我将 TOP 1000 添加到查询中,则需要 10 秒才能运行。
这可能是什么原因造成的?
SELECT *
FROM (SELECT l.PatientID,
l.LabID,
l.Result
FROM dbo.Labs l
JOIN (SELECT MAX(LabDate) maxDate,
PatientID,
LabID
FROM dbo.Labs
GROUP BY PatientID, LabID) s ON l.PatientID = s.PatientID
AND l.LabID = s.LabID
AND l.LabDate = s.maxDate) A
PIVOT(MIN(A.Result) FOR A.LabID IN ([1],[2],[3],[4],[5],[7],[8],[9],[10],[11],[12],[13],[14],[15],[16],[17])) p
执行计划:
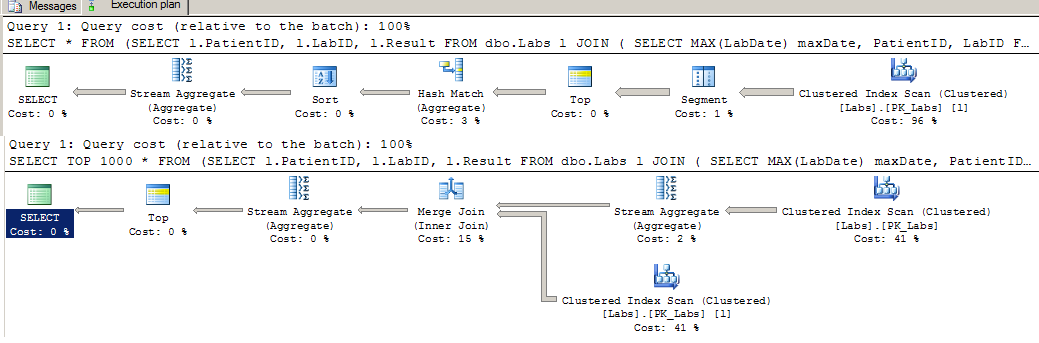
这个替代公式有同样的问题:
select
*
FROM (
SELECT
l.PatientID,
l.LabID,
l.Result
FROM dbo.Labs l
where l.LabDate = (
select
MAX(LabDate)
from Labs l2
where l2.PatientID = l.PatientID
and l2.LabID = l.LabID
)
) A
PIVOT(MIN(A.Result) FOR A.LabID IN ([1],[2],[3],[4],[5],[7],[8],[9],[10],[11],[12],[13],[14],[15],[16],[17])) p
最佳答案
SELECT TOP 1000
*
FROM (
SELECT patientId, labId, result,
DENSE_RANK() OVER (PARTITION BY patientId, labId ORDER BY labDate DESC) dr
FROM labs
) q
PIVOT (
MIN(result)
FOR
labId IN ([1],[2],[3],[4],[5],[7],[8],[9],[10],[11],[12],[13],[14],[15],[16],[17])
) p
WHERE dr = 1
ORDER BY
patientId
您也可以尝试像这样创建索引 View :
CREATE VIEW
v_labs_patient_lab
WITH SCHEMABINDING
AS
SELECT patientId, labId, COUNT_BIG(*) AS cnt
FROM dbo.labs
GROUP BY
patientId, labId
CREATE UNIQUE CLUSTERED INDEX
ux_labs_patient_lab
ON v_labs_patient_lab (patientId, labId)
并在查询中使用它:
SELECT TOP 1000
*
FROM (
SELECT lr.patientId, lr.labId, lr.result
FROM v_labs_patient_lab vl
CROSS APPLY
(
SELECT TOP 1 WITH TIES
result
FROM labs l
WHERE l.patientId = vl.patientId
AND l.labId = vl.labId
ORDER BY
l.labDate DESC
) lr
) q
PIVOT (
MIN(result)
FOR
labId IN ([1],[2],[3],[4],[5],[7],[8],[9],[10],[11],[12],[13],[14],[15],[16],[17])
) p
ORDER BY
patientId
关于sql - TOP 减慢查询速度,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/6681841/