我想从 this PDF 中抓取信息转换成以下格式:
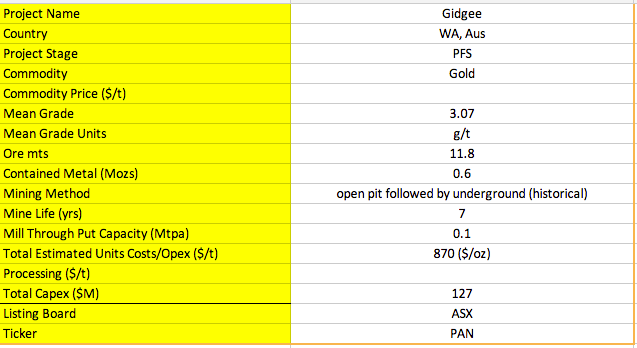
我在 PDF 中圈出了信息的来源区域。
如您所见,此 PDF 的格式是高度非结构化的,更糟糕的是,不同的 PDF 可能采用完全不同的布局,并且还会缺少信息。不熟悉挖矿的人已经很难解析此 PDF,因为并非所有信息都被清楚地标记。
所以我的问题是:是否有可能提出一种自动化方法来处理像这样的数千个 PDF?如果是这样,我将如何开始处理这项任务?我可以很好地使用 R 和 Python 进行编程。
我意识到这是一项非常困难(如果不是不可能的话)的任务。感谢您的输入。
最佳答案
我认为这并不像人们想象的那么困难。我同意它不会 100% 准确,但你肯定只是考虑了潜在的不准确性。我也不认为人类是 100% 准确的。
所以我建议您使用 PDF 库来提取文本,然后使用一组关键字匹配来尝试找到合适的信息。对于您提取的每个关键字,可能使用示例 PDF 中的红色圆圈标记原始 PDF。
然后在最终输出中不仅存储数据而且存储 PDF,以便人们可以检查数据并在适当时覆盖值。您需要定期检查覆盖的值并调整您的启发式方法以更好地应对。
您还需要一个测试台,以便您可以存储数以千计的测试文档并根据现有知识库验证任何代码更改。这让您有信心改变事情,并有理由确定您没有破坏任何重要的东西。
我的答案可能包含基于 ABCpdf 的概念。这就是我的工作。这就是我所知道的。 :-)
关于pdf - 从 PDF 中抓取非结构化信息,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/17102062/