使用spark保存记录时,有没有办法获取写入的记录数?虽然我知道它目前不在规范中,但我希望能够执行以下操作:
val count = df.write.csv(path)
或者,能够对步骤的结果进行内联计数(最好不只使用标准累加器)将(几乎)同样有效。 IE。:
dataset.countTo(count_var).filter({function}).countTo(filtered_count_var).collect()
有任何想法吗?
最佳答案
我会用 SparkListener 可以拦截onTaskEnd或 onStageCompleted可用于访问任务指标的事件。
任务指标为您提供 Spark 用于在 SQL 选项卡(在查询的详细信息中)显示指标的累加器。
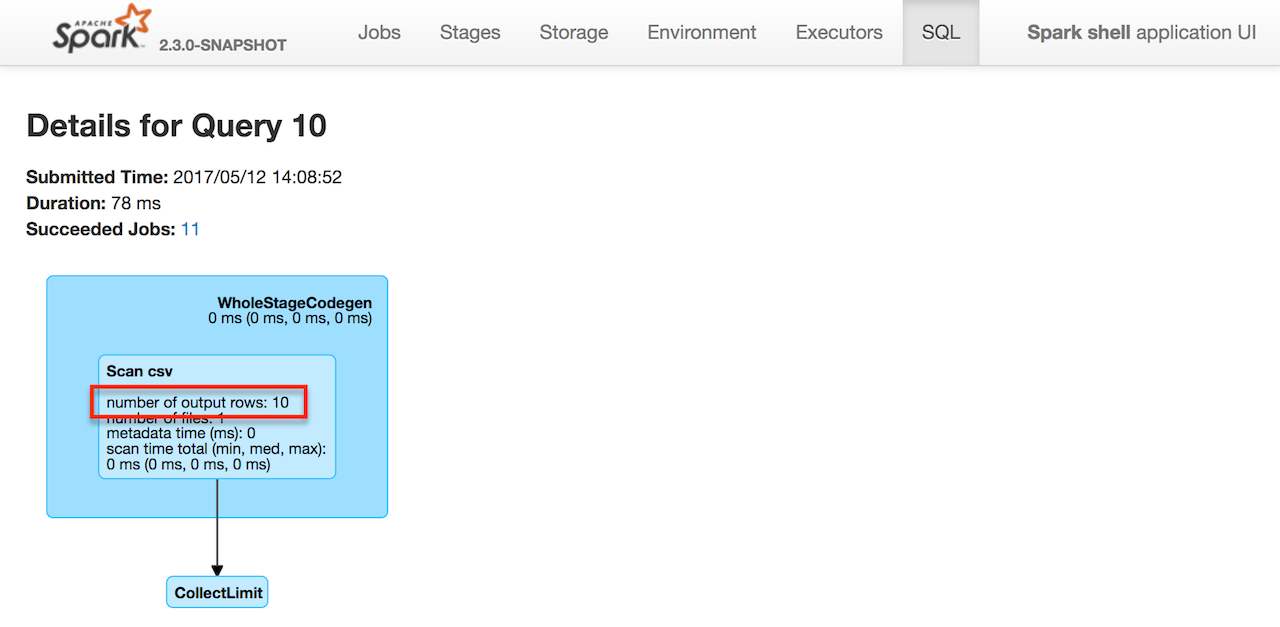
例如,以下查询:
spark.
read.
option("header", true).
csv("../datasets/people.csv").
limit(10).
write.
csv("people")
正好给出 10 个输出行,所以 Spark 知道它(你也可以)。
您还可以探索 Spark SQL 的 QueryExecutionListener :
The interface of query execution listener that can be used to analyze execution metrics.
您可以注册
QueryExecutionListener使用 ExecutionListenerManager 可用作 spark.listenerManager .scala> :type spark.listenerManager
org.apache.spark.sql.util.ExecutionListenerManager
scala> spark.listenerManager.
clear clone register unregister
我认为它更接近“裸机”,但之前没有使用过。
@D3V (在评论部分)提到访问
numOutputRows SQL 指标使用 QueryExecution结构化查询。值得考虑的东西。scala> :type q
org.apache.spark.sql.DataFrame
scala> :type q.queryExecution.executedPlan.metrics
Map[String,org.apache.spark.sql.execution.metric.SQLMetric]
q.queryExecution.executedPlan.metrics("numOutputRows").value
关于scala - 如何获取写入的记录数(使用DataFrameWriter的save操作)?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/43934168/