我只是不断收到关于
“在过去 24 小时内,Googlebot 在尝试访问您的 robots.txt 时遇到了 1 个错误。为确保我们没有抓取该文件中列出的任何网页,我们推迟了抓取。您网站的总体 robots.txt 错误率为 100.0 %。
您可以在网站站长工具中查看有关这些错误的更多详细信息。 ”
我搜索了它并告诉我在我的网站上添加 robots.txt
当我在 Google 网站管理员工具上测试 robots.txt 时,无法获取 robots.txt。
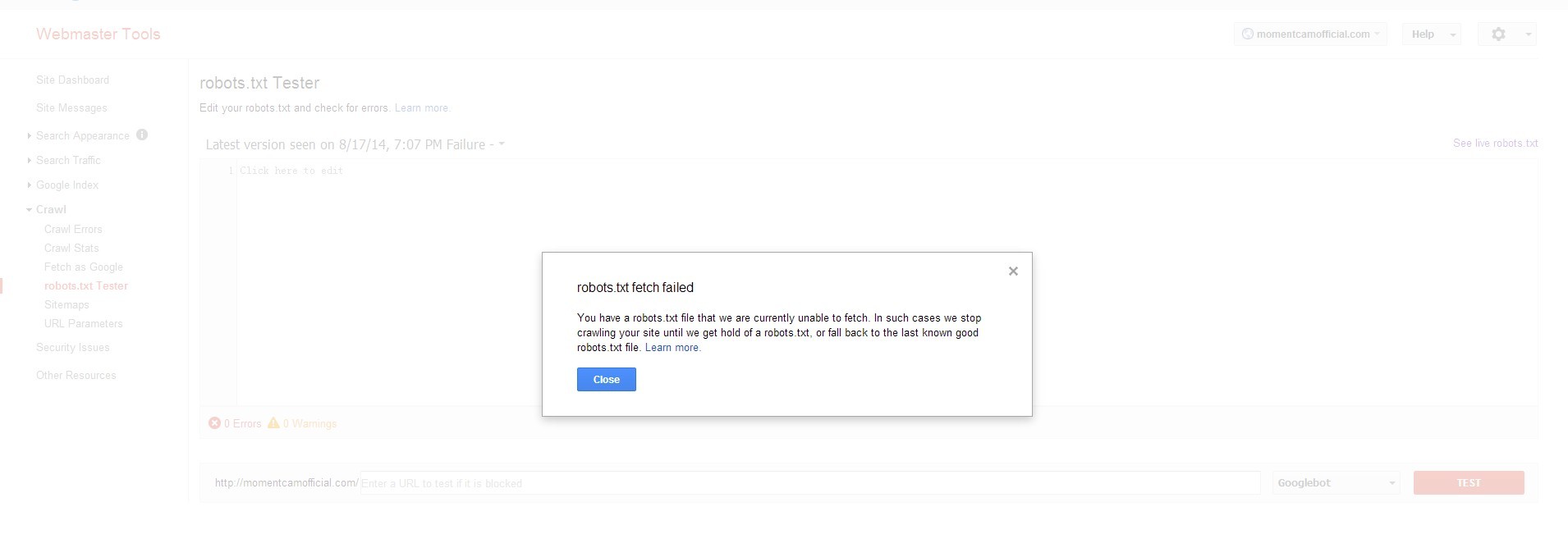
我想可能 robots.txt 被我的网站屏蔽了,但是当我测试时它说 GWT 允许。

' http://momentcamofficial.com/robots.txt '
这是 robots.txt 的内容:
用户代理: *
不允许:
那么为什么 Google 无法获取 robots.txt?我错过了什么......有人可以帮助我吗???
最佳答案
Before Googlebot crawls your site, it accesses your robots.txt file to determine if your site is blocking Google from crawling any pages or URLs. If your robots.txt file exists but is unreachable (in other words, if it doesn’t return a 200 or 404 HTTP status code), we’ll postpone our crawl rather than risk crawling URLs that you do not want crawled. When this happens, Googlebot will return to your site and crawl it as soon as we can successfully access your robots.txt file.
如您所知,robots.txt 是可选的,因此您无需创建,只需确保您的主机仅发送 200 或 404 http 状态即可。
关于search - 我如何解决 "Googlebot can' 无法访问您的网站”的问题?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/25355840/