当我从 Zeppelin 运行 Spark 作业时,该作业成功完成,但它停留在 YARN on 模式运行中。 问题是作业正在占用 YARN 中的资源。我认为 Zeppelin 坚持 YARN 的工作。
我该如何解决这个问题?
谢谢
最佳答案
有两种解决方案。
快速的方法是使用 "restart interpreter" functionality ,这是错误的命名,因为它只是停止解释器。在这种情况下,Yarn 中的 Spark 作业。
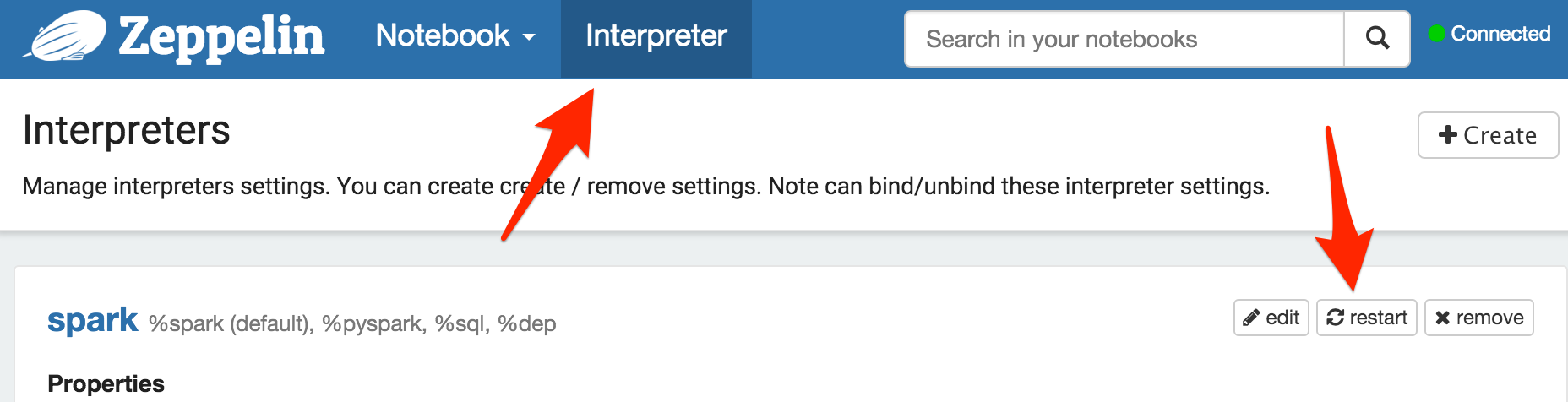{kind=link}
优雅的一种是配置 Zeppelin 以使用 dynamic allocation与星火。在这种情况下,Yarn 应用程序主机将继续运行,Spark 驱动程序将继续运行,但所有执行程序(它们是真正的资源消耗者)在不使用时都可以由 Yarn 释放。
关于apache-spark - Zeppelin 在 YARN 中坚持工作,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/48985340/