假设我有如下数据:
level start end
1 1 133.631 825.141
2 2 133.631 155.953
3 3 146.844 155.953
4 2 293.754 302.196
5 3 293.754 302.196
6 4 293.754 301.428
7 2 326.253 343.436
8 3 326.253 343.436
9 4 333.827 343.436
10 2 578.066 611.766
11 3 578.066 611.766
12 4 578.066 587.876
13 4 598.052 611.766
14 2 811.228 825.141
15 3 811.228 825.141
或这个:
level start end
1 1 3.60353 1112.62000
2 2 3.60353 20.35330
3 3 3.60353 8.77526
4 2 72.03720 143.60700
5 3 73.50530 101.13200
6 4 73.50530 81.64660
7 4 92.19030 101.13200
8 3 121.28500 143.60700
9 4 121.28500 128.25900
10 2 167.19700 185.04800
11 3 167.19700 183.44600
12 4 167.19700 182.84600
13 2 398.12300 418.64300
14 3 398.12300 418.64300
15 2 445.83600 454.54500
16 2 776.59400 798.34800
17 3 776.59400 796.64700
18 4 776.59400 795.91300
19 2 906.68800 915.89700
20 3 906.68800 915.89700
21 2 1099.44000 1112.62000
22 3 1099.44000 1112.62000
23 4 1100.14000 1112.62000
它们产生以下图形:
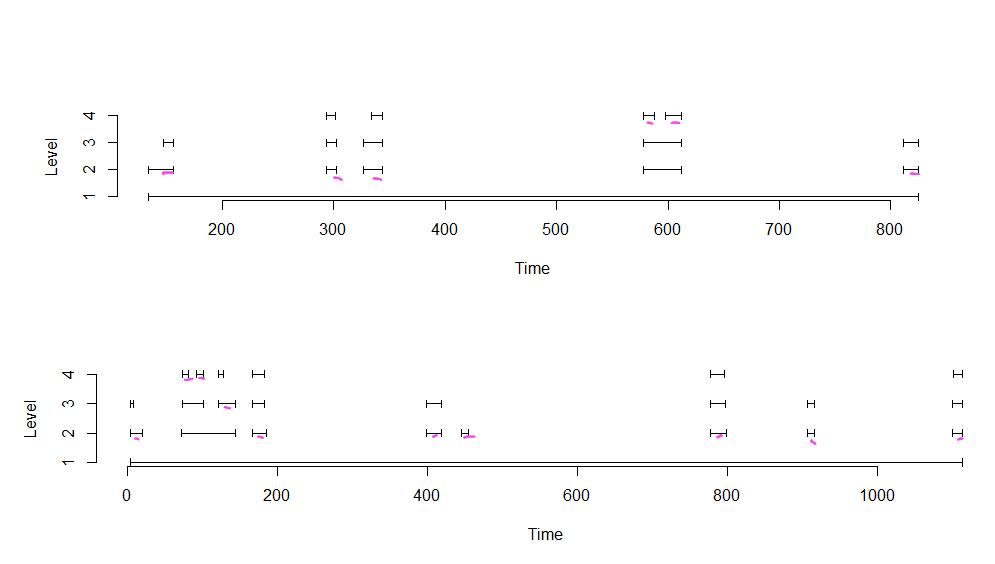
如您所见,有几个不同级别的时间间隔。 1级间隔始终跨越感兴趣时间的整个持续时间。级别2+的时间间隔较短。
我想做的是选择覆盖每个时间段的最大不重叠时间间隔数,其中每个时间间隔中包含最大的总时间。我用粉红色标记了那些。
对于小型数据框,可以强行执行此操作,但是显然应该有一些更合乎逻辑的方法来执行此操作。我有兴趣听到一些有关应该尝试的想法。
编辑:
我认为可以在这里帮助解决问题的一件事是“级别”列。结果来自Kleinberg的突发检测算法(“突发”包)。您将注意到这些级别是按层次组织的。相同数量的级别不能重叠。然而,水平连续增加,例如。连续行中的2,3,4可以重叠。
本质上,我认为这个问题可以缩短。以产生的级别为准,但删除级别1。这将是第二个示例的向量:
2 3 2 3 4 4 3 4 2 3 4 2 3 2 2 3 4 2 3 2 3 4
然后,查看2s ...如果少于或只有一个“3”,则该2是最长的间隔。但是,如果连续的2之间有两个或多个3,则应将这3个计数。对每个级别重复执行此操作。我认为应该起作用...?
例如
vec<-df$level %>% as.vector() %>% .[-1]
vec
#[1] 2 3 2 3 4 4 3 4 2 3 4 2 3 2 2 3 4 2 3 2 3 4
max(vec) #4
vec3<-vec #need to find two or more 4's between 3s
vec3[vec3==3]<-NA
names(vec3)<-cumsum(is.na(vec3))
0 1 1 2 2 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 8 8
2 NA 2 NA 4 4 NA 4 2 NA 4 2 NA 2 2 NA 4 2 NA 2 NA 4
vec3.res<-which(table(vec3,names(vec3))["4",]>1)
which(names(vec3)==names(vec3.res) & vec3==4) #5 6
上面的代码将第5行和第6行(相当于原始df中的第6行和第7行)标识为两个4介于3之间。也许某种使用这种方法的方法可能行得通?
最佳答案
好的,这是使用您的第二个数据集进行测试的一种方法。这可能并非在所有情况下都是正确的!
library(data.table)
dat <- fread("data.csv")
dat[,use:="maybe"]
make.pass <- function(dat,low,high,the.level,use) {
check <- dat[(use!="no" & level > the.level)]
check[,contained.by.above:=(low<=start & end<=high)]
check[,consecutive.contained.by.above:=
(contained.by.above &
!is.na(shift(contained.by.above,1)) &
shift(contained.by.above,1)),by=level]
if(!any(check[,consecutive.contained.by.above])) {
#Cause a side effect where we've learned we don't care:
dat[check[(contained.by.above),rownum],use:="no"]
print(check)
return("yes")
} else {
return("no")
}
}
dat[,rownum:=.I]
dat[level==1,use:=make.pass(dat,start,end,level,use),by=rownum]
dat
dat[use=="maybe" & level==2,use:=make.pass(dat,start,end,level,use),by=rownum]
dat
dat[use=="maybe" & level==3,use:=make.pass(dat,start,end,level,use),by=rownum]
dat
#Finally correct for last level
dat[use=="maybe" & level==4,use:="yes"]
我写出了这些最后步骤,以便您可以在自己的交互式 session 中进行跟踪以查看正在发生的情况(请参阅打印品以了解想法),但是您可以删除打印品,并将最后的步骤压缩为
lapply(1:dat[,max(level)-1], function(the.level) dat[use=="maybe" & level==the.level,use:=make.pass......]) 如果存在任意多个级别,则您肯定要使用这种形式主义,并在其后最后调用dat[use=="maybe" & level==max(level),use:="yes"]。输出:
> dat
level start end use rownum
1: 1 3.60353 1112.62000 no 1
2: 2 3.60353 20.35330 yes 2
3: 3 3.60353 8.77526 no 3
4: 2 72.03720 143.60700 no 4
5: 3 73.50530 101.13200 no 5
6: 4 73.50530 81.64660 yes 6
7: 4 92.19030 101.13200 yes 7
8: 3 121.28500 143.60700 yes 8
9: 4 121.28500 128.25900 no 9
10: 2 167.19700 185.04800 yes 10
11: 3 167.19700 183.44600 no 11
12: 4 167.19700 182.84600 no 12
13: 2 398.12300 418.64300 yes 13
14: 3 398.12300 418.64300 no 14
15: 2 445.83600 454.54500 yes 15
16: 2 776.59400 798.34800 yes 16
17: 3 776.59400 796.64700 no 17
18: 4 776.59400 795.91300 no 18
19: 2 906.68800 915.89700 yes 19
20: 3 906.68800 915.89700 no 20
21: 2 1099.44000 1112.62000 yes 21
22: 3 1099.44000 1112.62000 no 22
23: 4 1100.14000 1112.62000 no 23
level start end use rownum
如果这是正确的,则算法大致可描述如下:
by=rownum)。请记住 X ,将数据副本子集到所有更高级别的时间间隔。 让我知道您对此有何看法-这是一个粗略的草稿,某些方面可能不正确。
关于r - 确定最大数量和最长时间间隔,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/36015940/