我正在尝试对大量包含二进制数据的文件进行哈希处理,以便:
(1) 检查 future 是否有腐败,以及
(2) 消除重复文件(可能具有完全不同的名称和其他元数据)。
我知道 md5 和 sha1 以及它们的亲戚,但我的理解是它们是为安全而设计的,因此故意放慢速度以降低蛮力攻击的功效。相比之下,我希望算法运行得尽可能快,同时尽可能减少冲突。
有什么建议?
最佳答案
你是最对的。如果您的系统没有任何对手,考虑到它们的安全属性,使用加密散列函数是过度的。
碰撞取决于 位数 , b, 你的散列函数和 哈希值的数量 ,N,你估计计算。学术文献认为这种碰撞概率必须低于硬件错误概率,因此与逐字节比较数据相比,与哈希函数发生冲突的可能性更小 [ref1] , ref2 , ref3 , ref4 , ref5 ]。硬件错误概率在 2^-12 和 2^-15 [ref6] 范围内]。如果您希望生成 N=2^q 哈希值,那么您的碰撞概率可能由该等式给出,该等式已经考虑了 birthday paradox :
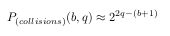
哈希函数的位数与其计算复杂度成正比。 因此,您有兴趣找到具有尽可能少的位的散列函数,同时能够将碰撞概率保持在可接受的值。
以下是有关如何进行分析的示例:
根据该等式,几种散列大小的碰撞概率如下:
现在你只需要决定你将使用哪个 64 位或 128 位的非加密哈希函数,知道 64 位它非常接近硬件错误概率(但会更快),而 128 位是一个更安全的选择(虽然更慢)。
您可以在下面找到一个从非加密哈希函数的维基百科中删除的小列表。我知道 Murmurhash3,它比任何加密哈希函数都要快得多:
关于hash - 用于数据完整性和重复数据删除的最佳散列算法有哪些?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/11696403/