我正在为 Dropbox 编写一个 DocumentsProvider。我试图按照 Google guidelines 来创建自定义提供程序,以及 Ian Lake 的 post on Medium 也是如此。
我正在尝试将该功能合并到存储访问框架中,从而表明有更多数据要加载。
我的 queryChildDocuments() 方法的相关部分如下所示:
@Override
public Cursor queryChildDocuments(final String parentDocumentId,
final String[] projection,
final String sortOrder) {
if (selfPermissionsFailed(getContext())) {
// Permissions have changed, abort!
return null;
}
// Create a cursor with either the requested fields, or the default projection if "projection" is null.
final MatrixCursor cursor = new MatrixCursor(projection != null ? projection : getDefaultDocumentProjection()){
// Indicate we will be batch loading
@Override
public Bundle getExtras() {
Bundle bundle = new Bundle();
bundle.putBoolean(DocumentsContract.EXTRA_LOADING, true);
bundle.putString(DocumentsContract.EXTRA_INFO, getContext().getResources().getString(R.string.requesting_data));
return bundle;
}
};
ListFolderResult result = null;
DbxClientV2 mDbxClient = DropboxClientFactory.getClient();
result = mDbxClient.files().listFolderBuilder(parentDocumentId).start();
if (result.getEntries().size() == 0) {
// Nothing in the dropbox folder
Log.d(TAG, "addRowsToQueryChildDocumentsCursor called mDbxClient.files().listFolder() but nothing was there!");
return;
}
// Setup notification so cursor will continue to build
cursor.setNotificationUri(getContext().getContentResolver(),
getChildDocumentsUri(parentDocumentId));
while (true) {
// Load the entries and notify listener
for (Metadata metadata : result.getEntries()) {
if (metadata instanceof FolderMetadata) {
includeFolder(cursor, (FolderMetadata) metadata);
} else if (metadata instanceof FileMetadata) {
includeFile(cursor, (FileMetadata) metadata);
}
}
// Notify for this batch
getContext().getContentResolver().notifyChange(getChildDocumentsUri(parentDocumentId), null);
// See if we are ready to exit
if (!result.getHasMore()) {
break;
}
result = mDbxClient.files().listFolderContinue(result.getCursor());
}
这一切正常。我按预期加载了数据的游标。我“免费”得到的(大概是由于附加包)是 SAF 会自动在屏幕顶部放置一个视觉效果,用于向用户发送文本(“请求数据”)和动画栏(在我的三星 Galaxy S7 运行 API 27) 来回移动以指示光标正在加载:
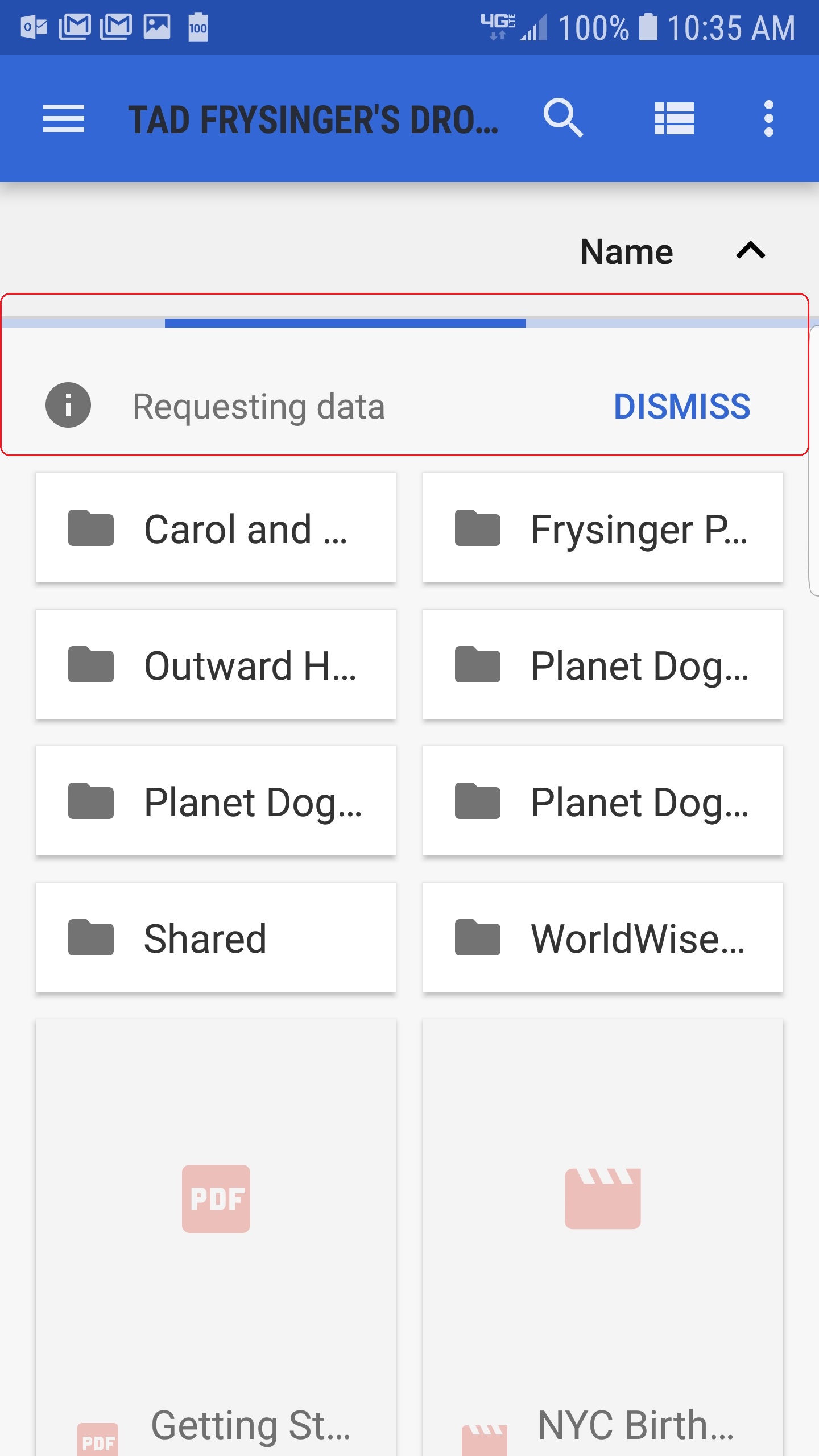
我的问题是 - 一旦我退出 fetch 循环并完成加载,我如何以编程方式摆脱屏幕顶部的 EXTRA_INFO 文本和 EXTRA_LOADING 动画?我已经搜索了 API,但没有看到任何看起来像是告诉 SAF 加载已完成的“信号”。
android 文档没有过多讨论这个功能,Ian 的 Medium 帖子只是简单地提到发送通知,以便光标知道自己刷新。两者都没有关于动画的任何说法。
最佳答案
我根据查看 com.android.documentsui 中的代码以及 AOSP 的其他区域以了解如何调用和使用自定义 DocumentsProvider 来回答这个问题:
我们的解决方案的关键是在模型通过加载器的返回更新自身之后显示/删除进度条。
此外,当 Model 实例被要求更新自身时,它会完全清除先前的数据并遍历当前光标以再次填充自身。这意味着我们的“第二次获取”应该只在所有数据都被检索到之后进行,并且它需要包括完整的数据集,而不仅仅是“第二次获取”。
最后 - 只有在从 queryChildDocuments() 返回 Cursor 之后,DirectoryLoader 才会在 Cursor 中注册一个内部类作为 ContentObserver。
因此,我们的解决方案变为:
在 DocumentsProvider.queryChildDocuments() 中,确定是否可以在一次传递中满足完整的结果集。
如果可以,那么只需加载并返回 Cursor,我们就完成了。
如果不能,那么:
If your provider is cloud-based, and you have some data cached or pinned locally, you may return the local data immediately, setting DocumentsContract.EXTRA_LOADING on the Cursor to indicate that you are still fetching additional data. Then, when the network data is available, you can send a change notification to trigger a requery and return the complete contents.
if (mFeatures.isContentPagingEnabled()) { Bundle queryArgs = new Bundle(); mModel.addQuerySortArgs(queryArgs); // TODO: At some point we don't want forced flags to override real paging... // and that point is when we have real paging. DebugFlags.addForcedPagingArgs(queryArgs); cursor = client.query(mUri, null, queryArgs, mSignal); } else { cursor = client.query( mUri, null, null, null, mModel.getDocumentSortQuery(), mSignal); } if (cursor == null) { throw new RemoteException("Provider returned null"); } cursor.registerContentObserver(mObserver);
cursor.setNotificationUri(getContext().getContentResolver(), DocumentsContract.buildChildDocumentsUri(, parentDocumentId));
getContext().getContentResolver().notifyChange(DocumentsContract.buildChildDocumentsUri(, parentDocumentId), null);
我在此过程中学到的一些重要提示:
MatrixCursor result = new MatrixCursor(projection != null ? projection : DEFAULT_DOCUMENT_PROJECTION) { @Override public Bundle getExtras() { Bundle bundle = new Bundle(); bundle.putBoolean(DocumentsContract.EXTRA_LOADING, true); return bundle; } };
如果您知道何时创建 Cursor 是否在一次获取中获取所有内容,这很好。
相反,如果您需要创建光标,填充它,然后在需要不同的模式后进行调整,例如:
private final Bundle b = new Bundle() MatrixCursor result = new MatrixCursor(projection != null ? projection : DEFAULT_DOCUMENT_PROJECTION) { @Override public Bundle getExtras() { return b; } };
然后你可以这样做:
result.getExtras().putBoolean(DocumentsContract.EXTRA_LOADING, true);
我发布了我的代码的相关部分来展示我是如何做到的,还有一些注释:
我的抽象 Provider 类中的 queryChildDocuments() 方法调用 createDocumentMatrixCursor() 方法,该方法可以根据 Provider 子类进行不同的实现:
@Override
public Cursor queryChildDocuments(final String parentDocumentId,
final String[] projection,
final String sortOrder) {
if (selfPermissionsFailed(getContext())) {
return null;
}
Log.d(TAG, "queryChildDocuments called for: " + parentDocumentId + ", calling createDocumentMatrixCursor");
// Create a cursor with either the requested fields, or the default projection if "projection" is null.
final MatrixCursor cursor = createDocumentMatrixCursor(projection != null ? projection : getDefaultDocumentProjection(), parentDocumentId);
addRowsToQueryChildDocumentsCursor(cursor, parentDocumentId, projection, sortOrder);
return cursor;
}
和我的 createDocumentMatrixCursor 的 DropboxProvider 实现:
@Override
/**
* Called to populate a sub-directory of the parent directory. This could be called multiple
* times for the same directory if (a) the user swipes down on the screen to refresh it, or
* (b) we previously started a BatchFetcher thread to gather data, and the BatchFetcher
* notified our Resolver (which then notifies the Cursor, which then kicks the Loader).
*/
protected MatrixCursor createDocumentMatrixCursor(String[] projection, final String parentDocumentId) {
MatrixCursor cursor = null;
final Bundle b = new Bundle();
cursor = new MatrixCursor(projection != null ? projection : getDefaultDocumentProjection()){
@Override
public Bundle getExtras() {
return b;
}
};
Log.d(TAG, "Creating Document MatrixCursor" );
if ( !(parentDocumentId.equals(oldParentDocumentId)) ) {
// Query in new sub-directory requested
Log.d(TAG, "New query detected for sub-directory with Id: " + parentDocumentId + " old Id was: " + oldParentDocumentId );
oldParentDocumentId = parentDocumentId;
// Make sure prior thread is cancelled if it was started
cancelBatchFetcher();
// Clear the cache
metadataCache.clear();
} else {
Log.d(TAG, "Requery detected for sub-directory with Id: " + parentDocumentId );
}
return cursor;
}
addrowsToQueryChildDocumentsCursor() 方法是我的抽象 Provider 类在调用它的 queryChildDocuments() 方法时调用的方法,也是子类实现的方法,也是批量获取大目录内容的所有魔法发生的地方。例如,我的 Dropbox 提供程序子类利用 Dropbox API 来获取它需要的数据,如下所示:
protected void addRowsToQueryChildDocumentsCursor(MatrixCursor cursor,
final String parentDocumentId,
String[] projection,
String sortOrder) {
Log.d(TAG, "addRowstoQueryChildDocumentsCursor called for: " + parentDocumentId);
try {
if ( DropboxClientFactory.needsInit()) {
Log.d(TAG, "In addRowsToQueryChildDocumentsCursor, initializing DropboxClientFactory");
DropboxClientFactory.init(accessToken);
}
final ListFolderResult dropBoxQueryResult;
DbxClientV2 mDbxClient = DropboxClientFactory.getClient();
if ( isReQuery() ) {
// We are querying again on the same sub-directory.
//
// Call method to populate the cursor with the current status of
// the pre-loaded data structure. This method will also clear the cache if
// the thread is done.
boolean fetcherIsLoading = false;
synchronized(this) {
populateResultsToCursor(metadataCache, cursor);
fetcherIsLoading = fetcherIsLoading();
}
if (!fetcherIsLoading) {
Log.d(TAG, "I believe batchFetcher is no longer loading any data, so clearing the cache");
// We are here because of the notification from the fetcher, so we are done with
// this cache.
metadataCache.clear();
clearCursorLoadingNotification(cursor);
} else {
Log.d(TAG, "I believe batchFetcher is still loading data, so leaving the cache alone.");
// Indicate we are still loading and bump the loader.
setCursorForLoadingNotification(cursor, parentDocumentId);
}
} else {
// New query
if (parentDocumentId.equals(accessToken)) {
// We are at the Dropbox root
dropBoxQueryResult = mDbxClient.files().listFolderBuilder("").withLimit(batchSize).start();
} else {
dropBoxQueryResult = mDbxClient.files().listFolderBuilder(parentDocumentId).withLimit(batchSize).start();
}
Log.d(TAG, "New query fetch got " + dropBoxQueryResult.getEntries().size() + " entries.");
if (dropBoxQueryResult.getEntries().size() == 0) {
// Nothing in the dropbox folder
Log.d(TAG, "I called mDbxClient.files().listFolder() but nothing was there!");
return;
}
// See if we are ready to exit
if (!dropBoxQueryResult.getHasMore()) {
// Store our results to the query
populateResultsToCursor(dropBoxQueryResult.getEntries(), cursor);
Log.d(TAG, "First fetch got all entries so I'm clearing the cache");
metadataCache.clear();
clearCursorLoadingNotification(cursor);
Log.d(TAG, "Directory retrieval is complete for parentDocumentId: " + parentDocumentId);
} else {
// Store our results to both the cache and cursor - cursor for the initial return,
// cache for when we come back after the Thread finishes
Log.d(TAG, "Fetched a batch and need to load more for parentDocumentId: " + parentDocumentId);
populateResultsToCacheAndCursor(dropBoxQueryResult.getEntries(), cursor);
// Set the getExtras()
setCursorForLoadingNotification(cursor, parentDocumentId);
// Register this cursor with the Resolver to get notified by Thread so Cursor will then notify loader to re-load
Log.d(TAG, "registering cursor for notificationUri on: " + getChildDocumentsUri(parentDocumentId).toString() + " and starting BatchFetcher");
cursor.setNotificationUri(getContext().getContentResolver(),getChildDocumentsUri(parentDocumentId));
// Start new thread
batchFetcher = new BatchFetcher(parentDocumentId, dropBoxQueryResult);
batchFetcher.start();
}
}
} catch (Exception e) {
Log.d(TAG, "In addRowsToQueryChildDocumentsCursor got exception, message was: " + e.getMessage());
}
线程(“BatchFetcher”)处理填充缓存,并在每次获取后通知解析器:
private class BatchFetcher extends Thread {
String mParentDocumentId;
ListFolderResult mListFolderResult;
boolean keepFetchin = true;
BatchFetcher(String parentDocumentId, ListFolderResult listFolderResult) {
mParentDocumentId = parentDocumentId;
mListFolderResult = listFolderResult;
}
@Override
public void interrupt() {
keepFetchin = false;
super.interrupt();
}
public void run() {
Log.d(TAG, "Starting run() method of BatchFetcher");
DbxClientV2 mDbxClient = DropboxClientFactory.getClient();
try {
mListFolderResult = mDbxClient.files().listFolderContinue(mListFolderResult.getCursor());
// Double check
if ( mListFolderResult.getEntries().size() == 0) {
// Still need to notify so that Loader will cause progress bar to be removed
getContext().getContentResolver().notifyChange(getChildDocumentsUri(mParentDocumentId), null);
return;
}
while (keepFetchin) {
populateResultsToCache(mListFolderResult.getEntries());
if (!mListFolderResult.getHasMore()) {
keepFetchin = false;
} else {
mListFolderResult = mDbxClient.files().listFolderContinue(mListFolderResult.getCursor());
// Double check
if ( mListFolderResult.getEntries().size() == 0) {
// Still need to notify so that Loader will cause progress bar to be removed
getContext().getContentResolver().notifyChange(getChildDocumentsUri(mParentDocumentId), null);
return;
}
}
// Notify Resolver of change in data, it will contact cursor which will restart loader which will load from cache.
Log.d(TAG, "BatchFetcher calling contentResolver to notify a change using notificationUri of: " + getChildDocumentsUri(mParentDocumentId).toString());
getContext().getContentResolver().notifyChange(getChildDocumentsUri(mParentDocumentId), null);
}
Log.d(TAG, "Ending run() method of BatchFetcher");
//TODO - need to have this return "bites" of data so text can be updated.
} catch (DbxException e) {
Log.d(TAG, "In BatchFetcher for parentDocumentId: " + mParentDocumentId + " got error, message was; " + e.getMessage());
}
}
}
关于android - 如何向存储访问框架表明我不再需要加载动画?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/51663222/