我是网络爬虫的新手,所以我在玩爬虫并试图爬取某个网站。
我正在使用 windows 上的 scrapy shell,只是试图为我想要访问的特定元素建立正确的 XPath。该元素是一个时间表,这是 HTML:
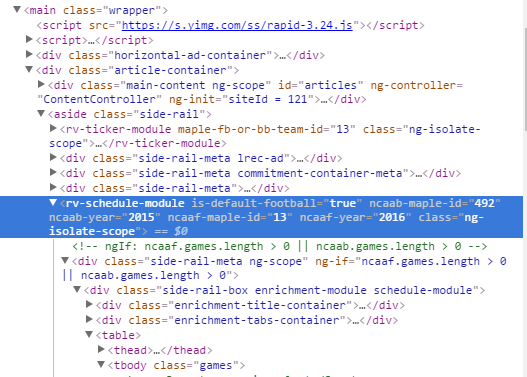
我正在尝试访问 rv-schedule-module 及其所有子节点。在 rv-schedule-module 之前,我可以访问所有节点,但除此之外,所有 XPath 调用都返回 null。例如:
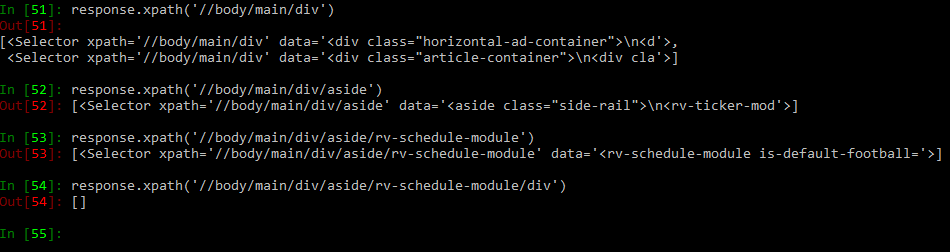
调用进程会返回数据,直到我想访问 rv-schedule-module 下的 div。该调用返回 null。
我究竟做错了什么?
最佳答案
就像我怀疑内容是动态创建的一样,因为它是由 javascript 处理的!
当您检查元素时,它会在那里,但如果您检查页面源,它不会。 Scrapy 本身不处理 javascript,你需要像 scrapy-splash 这样的东西或 Selenium .
有一个非常好的帖子,全能的 Alex 解释了如何使用它 - https://stackoverflow.com/a/30378765/2781701
关于html - 无法在 Scrapy 中使用 XPath 访问 HTML 元素,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/37797323/