{kind=link}
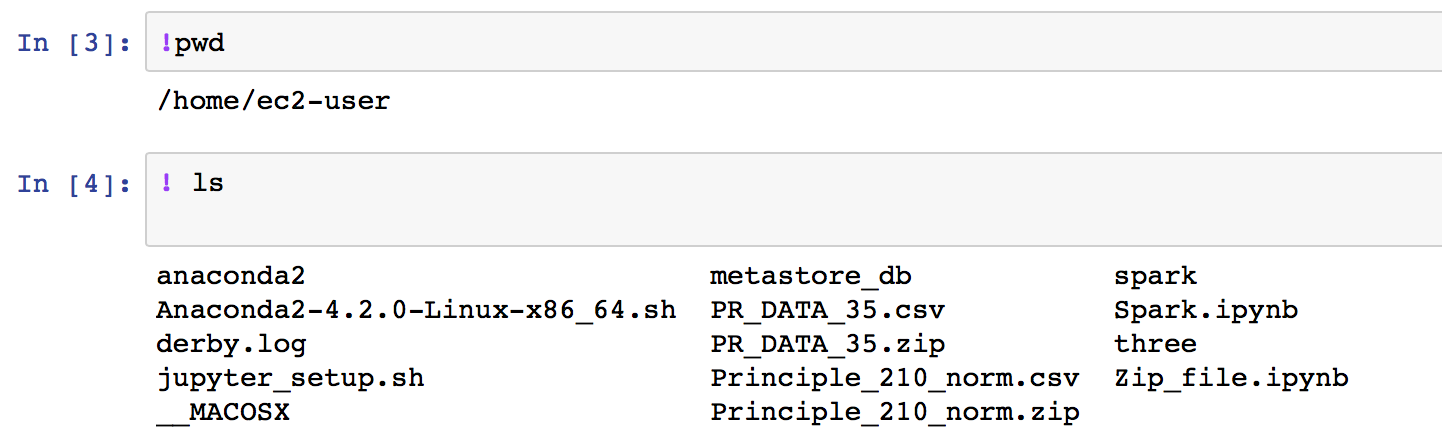
sparkDF = sqlContext.read.format('com.databricks.spark.csv').options(header='true').load('PR_DATA_35.csv')
ERROR_ ---------------------------------------------------------------------------------------------------------------------------------------------------- Py4JJavaError Traceback (most recent call last) in () ----> 1 sparkDF = sqlContext.read.format('com.databricks.spark.csv') .options(header='true').load('PR_DATA_35.csv')
/home/ec2-user/spark/python/pyspark/sql/readwriter.pyc in load(self, path, format, schema, **options) 157 self.options(**options) 158 if isinstance(path, basestring): --> 159 return self._df(self._jreader.load(path)) 160 elif path is not None: 161 if type(path) != list:
/home/ec2-user/spark/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py in call(self, *args) 1131 answer = self.gateway_client.send_command(command) 1132 return_value = get_return_value( -> 1133 answer, self.gateway_client, self.target_id, self.name) 1134 1135 for temp_arg in temp_args:
/home/ec2-user/spark/python/pyspark/sql/utils.pyc in deco(*a, **kw) 61 def deco(*a, **kw): 62 try: ---> 63 return f(*a, **kw) 64 except py4j.protocol.Py4JJavaError as e: 65 s = e.java_exception.toString()
/home/ec2-user/spark/python/lib/py4j-0.10.4-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name) 317 raise Py4JJavaError( 318 "An error occurred while calling {0}{1}{2}.\n". --> 319 format(target_id, ".", name), value) 320 else: 321 raise Py4JError(
Py4JJavaError: An error occurred while calling o312.load. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 5.0 failed 4 times, most recent failure: Lost task 0.3 in stage 5.0 (TID 23, 172.31.17.233, executor 0): java.io.FileNotFoundException: File file:/home/ec2-user/PR_DATA_35.csv does not exist It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved. at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.org$apache$spark$sql$execution$datasources$FileScanRDD$$anon$$readCurrentFile(FileScanRDD.scala:127) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:174) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:105) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:234) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:228) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:827) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:827) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323) at org.apache.spark.rdd.RDD.iterator(RDD.scala:287) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:108) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1499) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1487) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1486) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1486) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:814) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:814) at scala.Option.foreach(Option.scala:257) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:814) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1714) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1669) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1658) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:630) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2022) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2043) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2062) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:336) at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:38) at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:2853) at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2153) at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2153) at org.apache.spark.sql.Dataset$$anonfun$55.apply(Dataset.scala:2837) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:65) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:2836) at org.apache.spark.sql.Dataset.head(Dataset.scala:2153) at org.apache.spark.sql.Dataset.take(Dataset.scala:2366) at org.apache.spark.sql.execution.datasources.csv.TextInputCSVDataSource$.infer(CSVDataSource.scala:147) at org.apache.spark.sql.execution.datasources.csv.CSVDataSource.inferSchema(CSVDataSource.scala:62) at org.apache.spark.sql.execution.datasources.csv.CSVFileFormat.inferSchema(CSVFileFormat.scala:57) at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$7.apply(DataSource.scala:177) at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$7.apply(DataSource.scala:177) at scala.Option.orElse(Option.scala:289) at org.apache.spark.sql.execution.datasources.DataSource.getOrInferFileFormatSchema(DataSource.scala:176) at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:366) at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178) at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:156) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:280) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:214) at java.lang.Thread.run(Thread.java:748) Caused by: java.io.FileNotFoundException: File file:/home/ec2-user/PR_DATA_35.csv does not exist It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved. at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.org$apache$spark$sql$execution$datasources$FileScanRDD$$anon$$readCurrentFile(FileScanRDD.scala:127) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:174) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:105) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:234) at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:228) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:827) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:827) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323) at org.apache.spark.rdd.RDD.iterator(RDD.scala:287) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:108) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 more
任何帮助表示赞赏。谢谢
最佳答案
引起:java.io.FileNotFoundException:文件文件:/home/ec2-user/PR_DATA_35.csv不存在??
关于python - 使用 SQlcontext 在 spark 中加载我的 csv 时出错,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/49303286/