我正在尝试从 OpenNMT 运行基于 Lua 的程序。我已按照此处的步骤进行操作:http://forum.opennmt.net/t/text-summarization-on-gigaword-and-rouge-scoring/85
我使用了命令:
th train.lua -data textsum-train.t7 -save_model textsum1 -gpuid 0 1 2 3 4 5 6 7
我使用 8 个 GPU,但该过程仍然非常慢,就好像该过程在 CPU 上运行一样。请告诉我优化 GPU 使用率的解决方案是什么。
以下是 GP 使用情况的统计数据:
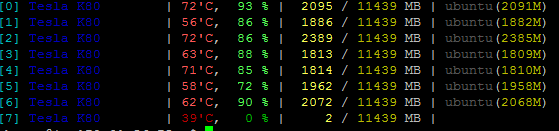
请告诉我如何使用完整的 GPU 使进程运行得更快。我可以使用 11GB,但该过程仅消耗 2GB 或更少。因此这个过程非常慢。
最佳答案
根据 OpenNMT documentation ,您需要从 gpuid 选项后面删除 0,因为 0 代表 CPU,并且您将有效地将训练速度降低到CPU 驱动的一个。
To use data parallelism, assign a list of GPU identifiers to the
-gpuidoption. For example:
th train.lua -data data/demo-train.t7 -save_model demo -gpuid 1 2 4will use the first, the second and the fourth GPU of the machine as returned by the CUDA API.
关于Lua 和 Torch 与 GPU 的问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/44426715/