你知道什么时候你有那么大的日志表,你只需要查看最后 X 行就知道当时发生了什么吗?
通常你可以这样做:
select top 100 *
from log_table
order by ID desc
显示最新的100条记录,但是是倒序的(当然是因为按DESC排序),例如:
100010
100009
100008
and so on..
但为了简单起见,我想查看它们发生的顺序的记录。 我可以通过运行以下查询来做到这一点:
select *
from(
select top 100 * from log_table order by ID desc
) a
order by a.id
我通过 ID desc 获取前 100 个订单,然后反转结果集。 它有效,但似乎没有必要运行 2 select 来产生这个结果。
我的问题是:有人有更好的主意吗?就像表格末尾的选择顶部一样?
编辑:
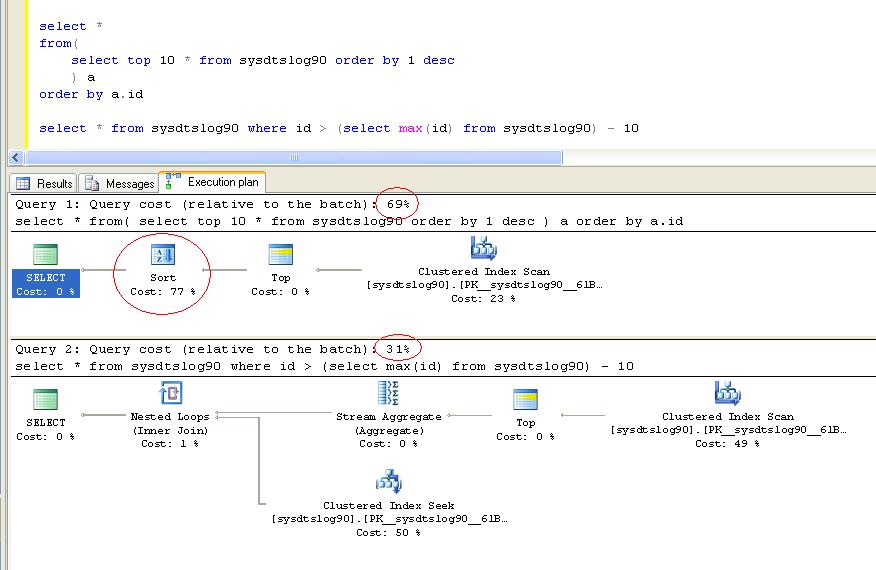
两个查询的执行计划:
看来Alex的想法很好,但David也是对的,只有一种选择和一种排序
编辑2: 设置统计IO ON:
(10 row(s) affected)
Table 'sysdtslog90'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 12, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
(10 row(s) affected)
Table 'sysdtslog90'. Scan count 2, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 12, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
最佳答案
but it seems kin of unnecessary to run 2 select to produce this result.
错了。这是必要的。
更多详细信息:查看查询的估计执行计划。它可能看起来像 ClusteredIndexScan -> Top -> 只有一种排序。内部查询的 OrderBy 不执行排序,它只是指示执行从表的“后面”读取。
关于sql - 反向选择 TOP *,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/10739523/